Auch in der sechsten Runde des etablierten KI-Benchmarks MLPerf dominiert Nvidia mit der zwei Jahre alten A100-GPU. Doch die Konkurrenz schläft nicht.
Der Benchmark MLPerf für Künstliche Intelligenz wird seit 2018 von MLCommons geleitet. Der Test soll einen transparenten Vergleich verschiedener Chip-Architekturen und Systemvarianten bei KI-Berechnungen ermöglichen.
Zu den teilnehmenden Unternehmen zählen Chip-Hersteller wie Nvidia, Google, Graphcore oder Intels Habana Labs sowie Server-Hersteller wie Inspur, Fujitsu oder Lenovo. Am diesjährigen MLPerf-Trainingsbenchmark 2.0 nahmen insgesamt 24 Unternehmen mit ihren Produkten teil.

Letztes Jahr schlug ein Graphcore IPU-POD16 mit 16 MK2000-Chips das erste Mal ein Nvidia DGX A100 640 System im Training eines ResNet-50-Modells - um 60 Sekunden. Nvidia hielt den Vergleich jedoch für unangemessen, da das eigene System lediglich acht Chips verbaut hat. So zeigte Nvidia im MLPerf Training 1.1. die beste Pro-Chip-Leistung.
MLPerf Training 2.0: Nvidia gehören 90 Prozent
Auch im diesjährigen Benchmark dominieren Nvidia-Systeme: Von allen Einreichungen im Benchmark sind 90 Prozent auf Nvidias KI-Hardware aufgebaut. Die restlichen drei Teilnehmer sind Googles TPUv4, Graphcores neue BOW-IPU und Intel Habana Labs Gaudi-2-Chip.
Alle Nvidia-Systeme setzen auf die zwei Jahre alte Nvidia A100 Tensor Core GPU in der 80 Gigabyte-Variante und nehmen an allen acht Trainingsbenchmarks im geschlossenen Wettbewerb teil. Google nimmt lediglich am RetinaNet- und Mask R-CNN-Benchmark teil, Graphcore und Habana Labs lediglich am BERT- und RestNet-50-Benchmark.
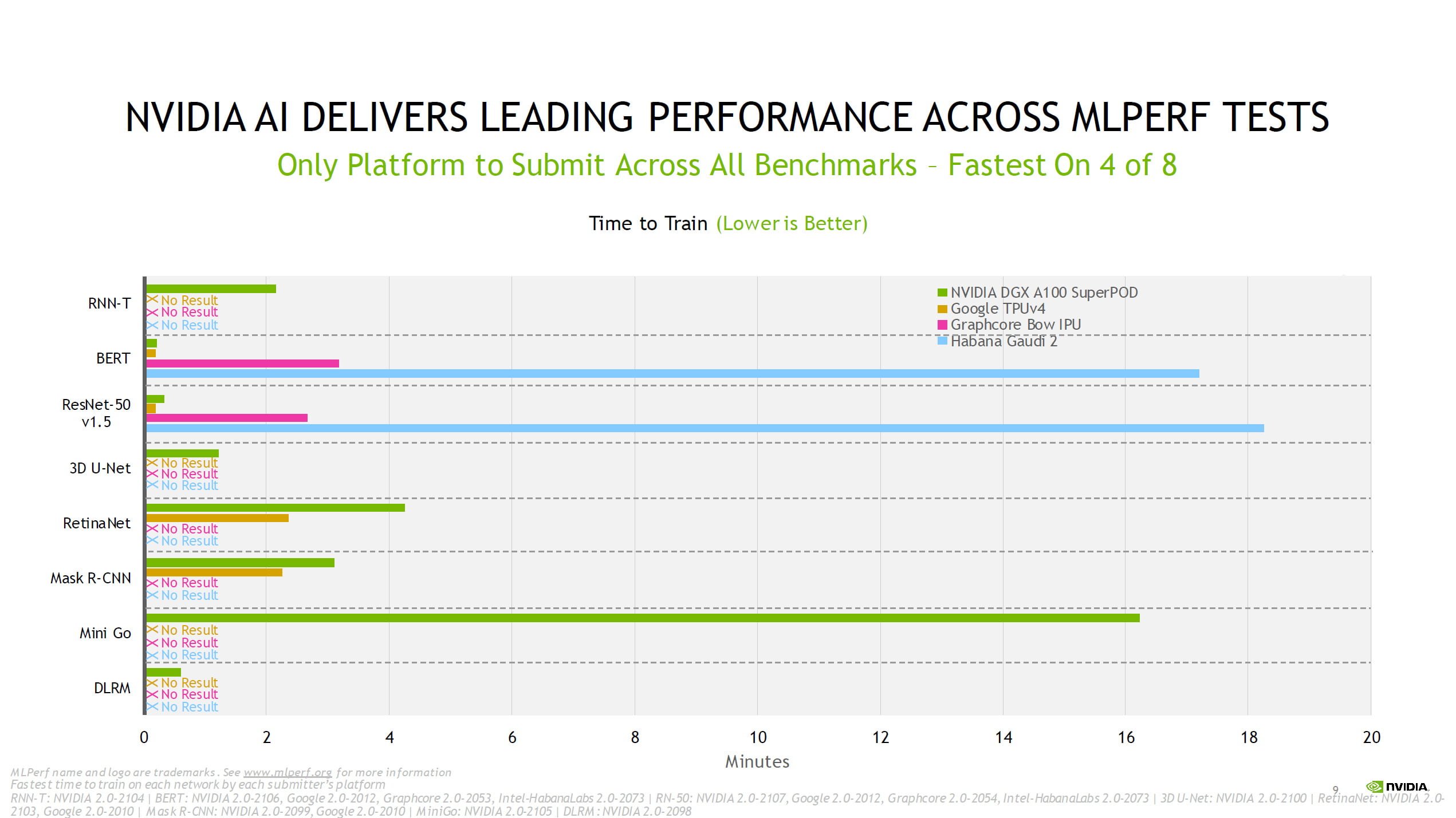
Laut Nvidia behalte die A100 zudem ihre Führungsposition in einem Leistung-pro-Chip-Vergleich und sei in sechs der acht Tests am schnellsten.
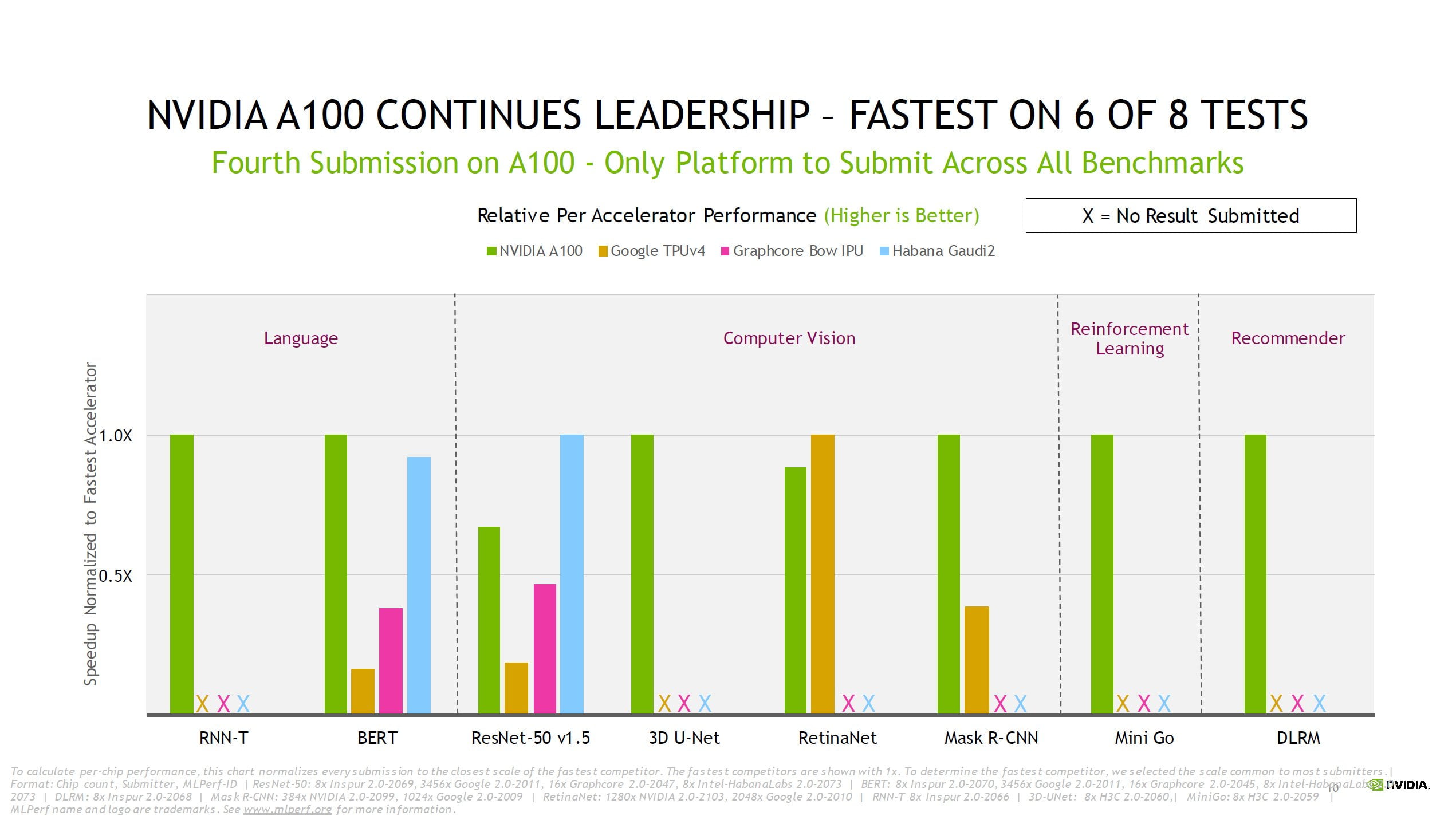
Seit Beginn der ersten Tests 2018 habe Nvidias KI-Plattform durch den Sprung von V100 auf A100 sowie zahlreichen Software-Verbesserungen die Trainingsleistung um den Faktor 23 gesteigert, so das Unternehmen.
Nvidia sieht einen der größten Vorteile der eigenen Plattform in ihrer Vielfältigkeit: Selbst verhältnismäßig simple KI-Anwendungen wie per Spracheingabe Fragen zu einem Bild zu stellen, benötigten mehrere KI-Modelle.

Entwickler:innen müssten diese Modelle schnell und flexibel entwerfen, trainieren, einsetzen und optimieren können. Daher seien die Vielfältigkeit von KI-Hardware - also die Fähigkeit, jedes Modell in MLPerf und darüber hinaus auszuführen - und eine hohe Leistung entscheidend, um reale KI-Produkte zu entwickeln.
Nvidia stellt zudem heraus, als einziges Unternehmen reale Performance in Supercomputer-Konfigurationen zeigen zu können. Das sei wichtig, um große KI-Modelle wie GPT-3 oder Megatron Turing NLG zu trainieren.
Graphcore zeigt Leistungssprung und Kooperationsbereitschaft
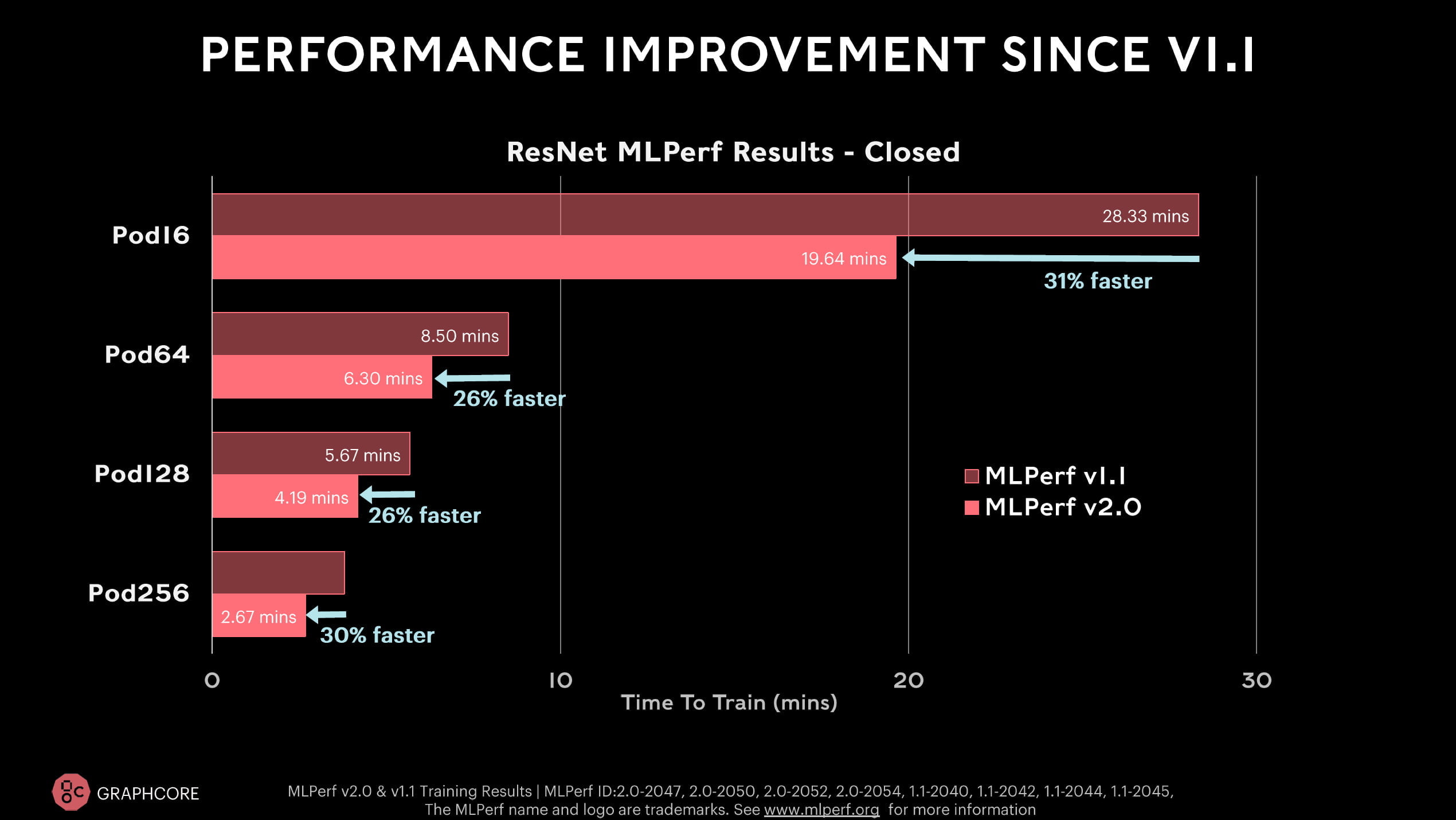
Der britische Chip-Hersteller Graphcore geht das erste Mal mit der neuen BOW-IPU ins Rennen. Mit der besseren Hardware und Softwareverbesserungen erreicht Graphcore im ResNet-50-Benchmark eine 26 bis 31 Prozent schnellere Trainingszeit, im BERT-Benchmark sind es im Schnitt sogar 36 bis 37 Prozent - je nach System.
Das erste Mal nimmt auch ein externes Unternehmen mit einem Graphcore-System am Benchmark teil. Baidu reicht BERT-Werte für ein Bow-Pod16 und ein Bow-Pod64 ein und nutzt dabei das in China verbreitete KI-Framework PaddlePaddle.
Die erreichten Werte im Training liegen auf dem Niveau von Grapcores Einreichungen im internen PopART-Framework. Für Graphcore ist das ein Zeichen, dass die eigenen Chips auch in anderen Frameworks gute Ergebnisse erzielen können.
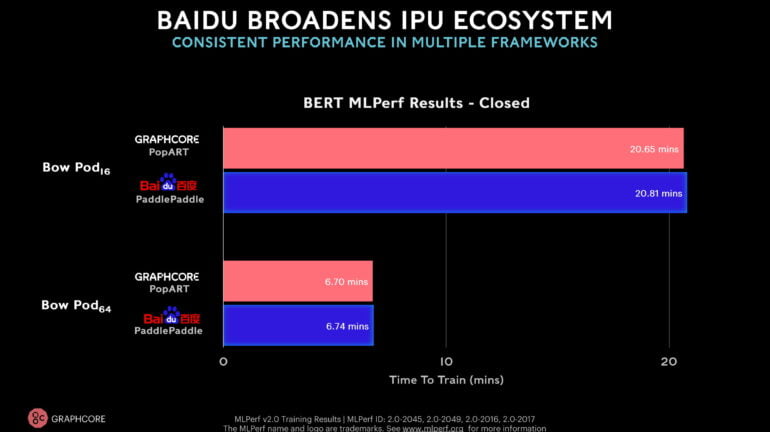
Im ResNet-50-Benchmark liegt das neue Bow-Pod16 laut Graphcore deutlich vor Nvidias DGX-A100-Server und biete konkurrenzfähige Preise.

Graphcore will nicht direkt mit Nvidia konkurrieren
In einem Presse-Briefing zu den MLPerf-Ergebnissen weist Graphcore auf die unterschiedliche Architektur der eigenen Produkte hin: Nvidia, Google und Intel produzieren ähnliche Vektor-Prozessoren, Graphcores IPU sei hingegen ein Graph-Prozessor.
Die Teilnahme am MLPerf-Benchmark solle daher primär zeigen, dass Graphcores IPU vergleichbare Leistung bringen könne. Die Hardware biete aber noch mehr.
"Für uns wäre es sehr schwierig, nur Nvidia zu kopieren und ihre Produkte zu bauen, denn Nvidia baut bereits die besten GPUs. Jeder, der etwas Vergleichbares baut, wird es sehr schwer haben, sich von Nvidia abzuheben - also machen wir etwas anderes", so Graphcore.
Das Unternehmen arbeite mit unterschiedlichen Kunden zusammen, die eine Vielzahl von Architekturen und Modellen einsetze - darunter solche, die von anderen MLPerf-Teilnehmern noch als experimentell bezeichnet würden, etwa Vision Transformer. Die tauchen nicht im Benchmark auf.
Ebenso habe man im offenen MLPerf-Benchmark Ergebnisse eines modifizierten RNN-T-Modells eingereicht, das in Kooperation mit einem Unternehmen entwickelt wurde. Das unterscheide sich aber vom RNN-T-Modell im geschlossenen Wettbewerb. Der als Industriestandard entworfene KI-Benchmark ist zumindest dem britischen Unternehmen wohl noch nicht flexibel genug.
Wesentliches Differenzierungsmerkmal gegenüber Nvidia sei für Graphcore außerdem die aktuell deutlich bessere Leistung in Graph-Neural-Networks, die geringe Batch-Größen nutzen, sowie eine dynamische Speichernutzung benötigten.
Auf das EfficientNet-Modell profitiere von Graphcores IPUs. In beiden Fällen verortet das Unternehmen den Vorsprung gegen GPUs in der anderen Chip-Architektur der eigenen Produkte.
Kürzlich verkündete Graphcore zudem eine Kooperation mit dem deutschen KI-Startup Aleph Alpha.
Alle Ergebnisse und weitere Informationen gibt es auf der Webseite des MLCommons MLPerf-Benchmark.