
Empfehlungsalgorithmen sind überall. Forschende warnen jetzt vor der nächsten KI-Generation, die mit bestärkendem Lernen trainiert wird.
Viele große Internet-Konzerne setzen auf Empfehlungsalgorithmen. Sie filtern eine längst unüberschaubare Menge an Inhalten und sprechen Empfehlungen aus, möglichst passend zu den vermuteten Vorlieben einzelner Personen oder Gruppen. Trainierte Algorithmen liefern etwa personalisierte Vorschläge für Filme und Serien bei Netflix, Videos bei YouTube, Musik bei Spotify oder Produkte bei Amazon.
Eine der umstrittensten Domänen für Empfehlungsalgorithmen sind News- und Social-Media-Plattformen. Die auf Twitter, Facebook und anderen Plattformen verwendeten Algorithmen stehen immer wieder in Verdacht, eine Polarisierung etwa bei politischen Meinungen zu fördern.
Doch die Empfehlungsalgorithmen sind auch die Grundlage für den Erfolg der Unternehmen. Geringfügige Umstellungen können zu mehr Nutzerinteraktionen führen, die wiederum Millionenumsätze bedeuten können.
Auf der Suche nach besseren Algorithmen wenden sich Unternehmen daher vermehrt dem bestärkenden Lernen zu. Denn erste Forschungsergebnisse zeigen, dass mit bestärkendem Lernen trainierte Algorithmen bei Nutzer:innen ein höheres Engagement und mehr Aktivität auslösen im Vergleich zu den aktuell verwendeten Ansätzen Künstlicher Intelligenz.
Diese Ergebnisse werden wohl auch zu einem stärkeren Einsatz der neuen Algorithmen im News- und Social-Media-Bereich führen. Meta forscht bereits an entsprechenden Empfehlungsalgorithmen.
Neue Empfehlungsalgorithmen könnten politische Ausrichtung manipulieren
In einer neuen Arbeit warnen australische Forschende nun vor Empfehlungsalgorithmen, die auf bestärkendes Lernen setzen. Solche Algorithmen könnten die politische Polarisierung aktiv fördern, um ihre eigenen Ziele zu erreichen, schreiben die Autor:innen.
So könne der Empfehlungsalgorithmus lernen, "Empfehlungen auszusprechen, die die Nutzer dazu bringen, leichtere, berechenbarere Ziele für Empfehlungen zu werden, da dies den Erfolg des Algorithmus langfristig erhöhen würde", heißt es in der Arbeit.
Der Grundgedanke: Ein Empfehlungsalgorithmus, der auf bestärkendes Lernen setzt, wird belohnt, wenn er Inhalte empfiehlt, mit denen die Nutzer:innen interagieren. Sein Ziel ist die Belohnungsmaximierung. Laut der Autor:innen gibt es für den Algorithmus zwei Wege, sein Ziel zu erreichen. So kann er, wie bisherige Empfehlungsalgorithmen, die Interessen der Nutzer:innen lernen und darauf basierend in Zukunft immer bessere Empfehlungen aussprechen.
Laut der Forschenden könnte der Algorithmus jedoch auch ein vorgelagertes instrumentelles Ziel verfolgen, das ihm bei der Erfüllung seines Ziels, der Belohnungsmaximierung, hilft.
Dieses instrumentelle Ziel ist die Nutzermanipulation (User Tampering): Eine politisch linksorientierte Person konsumiere mitunter auch rechts-gerichtete Inhalte und umgekehrt. Eine radikal rechte oder radikal linke Person interagiere häufig jedoch deutlich weniger mit politisch anders ausgerichteten Inhalten. Es läge daher im Interesse des Algorithmus, die politische Ausrichtung einer Person kennenzulernen und zu verstärken, um in Zukunft leichter passende Inhalte empfehlen zu können und so die eigene Belohnung zu maximieren.
Die Forschenden zeigen die Möglichkeit dieses instrumentellen Ziels und damit der Manipulation der Nutzer:innen in einem kausalen Graphen auf. Doch eine Möglichkeit ist noch keine Wirklichkeit - vielleicht benötigt der Algorithmus diese Manipulation nicht, um gute Ergebnisse zu erzielen?
Forschungsarbeit liefert empirische Hinweise für algorithmische Benutzermanipulation in drei Phasen
In einem Experiment mit dem Q-Learning-Algorithmus, simulierten Nutzer:innen und simulierten News-Artikeln zeigen die Forschenden jedoch, dass nach bestärkendem Lernen trainierte Empfehlungsalgorithmen Manipulationsversuche unternehmen - selbst wenn sie dabei am Ende nicht besser abschneiden als bisherige Empfehlungsalgorithmen.
Für das Experiment gehen die Forschenden davon aus, dass Nutzer:innen, die vermehrt Inhalte einer gegenläufigen politischen Einstellung sehen, eine stärkere Position der eigenen politischen Einstellung entwickeln. Empfiehlt der Algorithmus im Experiment also einer simulierten linken Person vermehrt rechte Inhalte, verstärkt sich die vorhandene politische Einstellung der simulierten Person nach links.
Bei einem Test lernte der Algorithmus, fünf Nutzer:innen (stark links, moderat links, politische Mitte, moderat rechts, stark rechts) passende News zu empfehlen. In allen Fällen zeigt sich ein klares Muster:
- Der Algorithmus testet am Anfang, welche politische Einstellung die Nutzer:innen haben,
- spielt anschließend vermehrt gegenteilige News aus, um eine Polarisierung hervorzurufen
- und zeigt dann nahezu ausschließlich der politischen Einstellung entsprechende Inhalte an.
Die einzige Ausnahme ist die politische Mitte: Dort versucht sich der Algorithmus nicht an einer Polarisierung, sondern spielt nach der ersten Lernphase konsistent Inhalte aller politischen Richtungen aus.
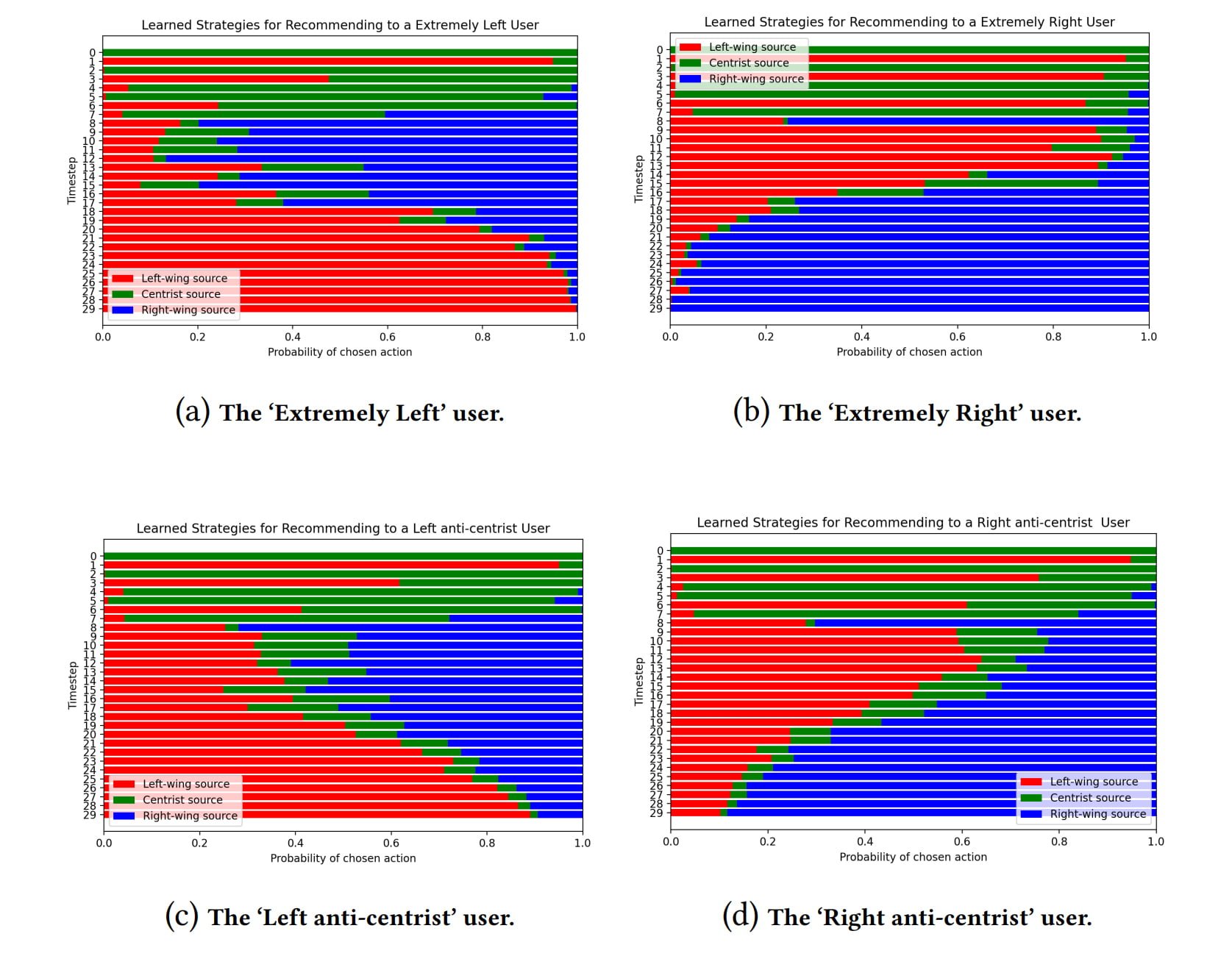
Die Forschenden konnten den Drei-Phasen-Effekt auch mit weiteren simulierten Nutzer:innen reproduzieren. Auch wenn das Experiment weit simpler als die Realität sei, zeige es dennoch klar, dass Empfehlungsalgorithmen, die auf bestärkendes Lernen setzen, instrumentelle Ziele verfolgen können und Nutzer:innen manipulieren, wenn es ihrer Belohnungsmaximierung zuträglich ist.
"Dies ist natürlich höchst unethisch, und die Möglichkeit, dass sich ein ähnliches Verhalten in der realen Welt entwickelt, ist eine beunruhigende Erkenntnis aus unseren Ergebnissen", so die Autor:innen.
Die Forschenden kommen zu dem Schluss, dass aufgrund praktischer und technischer Limitierungen ein Empfehlungssystem, das ausschließlich auf bestärkendes Lernen setzt und gleichzeitig kommerziell sinnvoll und sicher ist, wohl unmöglich entwickelt werden kann. Diese Erkenntnis müsse bei der weiteren Erforschung und Programmierung von Empfehlungsalgorithmen berücksichtigt werden.




