
Nur 16 Monate nach der Einführung des Sprach-Benchmarks SuperGLUE haben Google und Microsoft den anspruchsvollen Test gelöst.
KI-Systeme haben in den letzten Jahren große Sprünge in der Computerlinguistik ermöglicht. Gemessen werden diese Fortschritte mit Benchmarks für Sprachaufgaben wie etwa Textgenerierung, Verständnistests oder maschinelle Zusammenfassungen.
Die schnellen Fortschritte der letzten Monate veranlassten KI-Forscher unter anderem von Deepmind und Facebook den bis dato häufig genutzten GLUE-Benchmark (General Language Understanding Evaluation) durch SuperGLUE zu ersetzen.
Der Benchmark besteht aus acht Sprachaufgaben: Eine Sprach-KI muss zum Beispiel Fragen zu einem kurzen Wikipedia-Abschnitt beantworten, sie muss erkennen, in welchem Kontext ein Wort mit mehreren Bedeutungen in einem Textabschnitt genutzt wird oder auf welches Wort sich ein doppeldeutiges Pronomen bezieht.
Diese vielfältigen Aufgaben kann Sprach-KI nur mit einer grundlegende Generalisierung ihrer Fähigkeiten lösen. Auf eine einzelne Aufgabe trainierte KIs versagen im Benchmark.
Google und Microsoft knacken SuperGLUE
Bei der Einführung von SuperGLUE im August 2019 lagen ganze 20 Punkte Abstand zwischen der besten Künstlichen Intelligenz und dem menschlichen Vergleichswert von 89,8. Nun haben zwei KI-Systeme von Google und Microsoft die Marke von 90 geknackt - und damit SuperGLUE gelöst.
Googles 11 Milliarden Paramter KI-System „T5 + Meena“ erreicht einen Wert von 90.2, Microsofts DeBERTa einen Wert von 90.3.
Bisher hat Google keine Details zum eigenen System veröffentlicht. Der Name legt aber nahe, dass es sich um eine Weiterentwicklung des Systems hinter dem Meena-Chatbot handelt, den Google Anfang 2020 vorstellte.
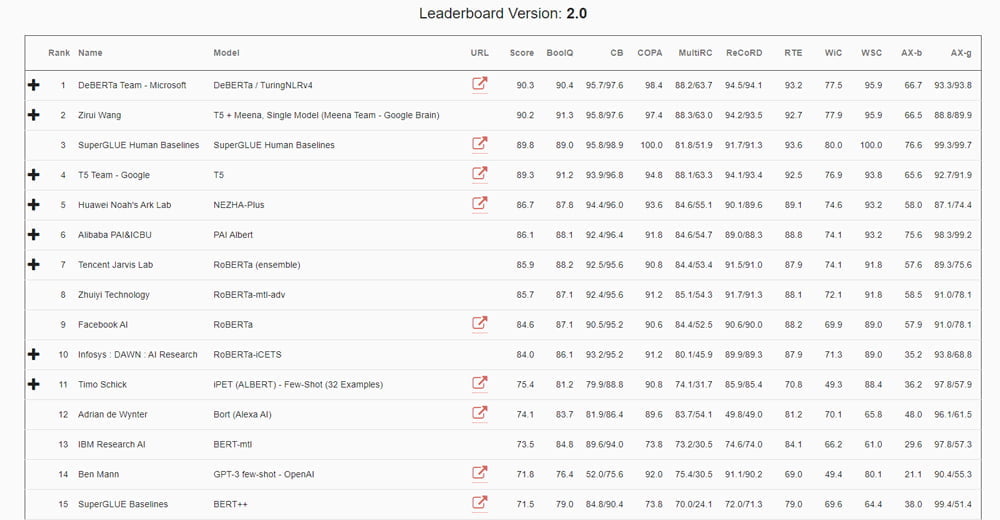
Microsoft hat dagegen bereits Details zu DeBERTa in einem Blog-Beitrag geteilt. Wie auch Googles System setzt Microsoft auf den Aufmerksamkeits-Mechanismus, der als Transformer-Architektur die Computerlinguistik revolutioniert hat und sich gerade in anderen KI-Anwendungen wie der Bildanalyse und -generierung etabliert. Wir erklären Transformer in unserem aktuellen KI-Podcast im Detail.

OpenAIs mächtige Sprach-KI GPT-3 schafft es übrigens nicht in die Bestenliste des SuperGLUE-Benchmarks: GPT-3 setzt zwar ebenfalls auf die Transformer-Architektur, wird aber anders trainiert als BERT, RoBERTa oder DeBERTa. Dadurch ist sie zwar in der Textgenerierung die Nummer eins, kann aber in anderen Aufgaben nicht mithalten.
DeBERTa verarbeitet Wortpositionen besser als Vorgängermodelle
DeBERTa mischt Googles Sprach-KI BERT mit Facebooks Weiterentwicklung RoBERTa. Microsofts DeBERTa wurde bereits letztes Jahr als Open Source veröffentlicht. Die SuperGLUE-Version ist jedoch eine neu trainierte Variante mit 1,5 Milliarden Parametern.
Trainiert wurde DeBERTa mit dem sogenannten Masked Language Modeling (MLM): Die KI muss Wörter erraten, die in einem Satz verborgen (maskiert) wurden. Dafür verwendet DeBERTa den Inhalt und die relative Position der umliegenden Wörter im Satz – soweit ist das bekannt von anderen Modellen wie BERT.
Neu bei DeBERTa ist, dass die Informationen über einen Inhalt und dessen relative Position in zwei unterschiedlichen Vektoren repräsentiert werden. Bei Modellen wie BERT wird jedes Wort durch einen einzigen Vektor repräsentiert, der die Inhalts- und Positionsinformation als Summe abbildet.
Die Trennung in zwei Vektoren erlaube der KI, die Abhängigkeit zwischen Wörtern besser zu erfassen, da Inhalts- und Positionsinformationen besser dargestellt werden. Dadurch erkennt DeBERTa etwa, dass die Abhängigkeit zwischen den Wörtern Deep und Learning wesentlich stärker ist, wenn sie nebeneinanderstehen, anstatt in verschiedenen Sätzen eines Abschnitts vorzukommen.
DeBERTa repräsentiert neben Inhalt und relativer Position auch die absolute Position eines Wortes im Satz. Modelle wie BERT repräsentieren bisher lediglich die relative Position eines Wortes, also die Position eines Wortes in Relation zu anderen Wörtern.
Die absolute Position liefert wichtige Informationen über die syntaktische Rolle, die ein Wort in einem Satz einnimmt: Im Satz "Ein neuer Laden öffnet neben dem neuen Einkaufzentrum" ergibt sich erst aufgrund der Position des Wortes Laden, dass Laden und nicht Einkaufszentrum das Subjekt des Satzes ist.
Mit diesen zusätzlichen Informationen ausgestattet, ist DeBERTa wesentlich besser darin, die passenden maskierten Wörter vorherzusagen. Ein so trainiertes Netz kann anschließend alle möglichen Sprachaufgaben angehen – so wie den SuperGLUE-Benchmark.
DeBERTa wird Teil von Microsoft Software
Die neue Version von DeBERTa soll wie die vorherige als Open Source veröffentlicht und in der nächsten Version von Microsofts Turing-Modell integriert werden, das Produkte wie Bing, Office, Dynamics und Azure Cognitive Systems bei Sprach- und Textaufgaben unterstützt.
Ob Google ähnliche Pläne hat, ist bisher nicht bekannt. Ein KI-System wie T-5, das Sprachaufgaben lösen kann, könnte jedoch den Google Assistant oder die Google Suche verbessern. Die Google Suche setzt bereits auf BERT.
Die Ergebnisse von Microsoft und Google zeigen, dass SuperGLUE als Benchmark nur ein gutes Jahr nach der Einführung schon wieder ausgedient hat. Das demonstriert eindrucksvoll den KI-Fortschritt der letzten Monate bei der Sprachverarbeitung.
Jetzt braucht es neue Benchmarks für die Messung zukünftiger Fortschritte. Mögliche Kandidaten gibt es bereits, etwa Dynabench, eine Forschungsplattform, die statische Benchmarks wie SuperGLUE ablösen will und sich ständig entwickelnde Benchmarks für verschiede Sprachaufgaben bietet, darunter einige "noch lange nicht gelöste Aufgaben".
Via: Arxiv




