
OpenAIs DALL-E 2 setzt auf eine ganze Reihe von Sicherheitsmaßnahmen, um einen potenziellen Missbrauch zu stoppen. Jetzt gibt OpenAI einen tiefen Einblick in den Trainingsprozess.
Im April gab OpenAI das erste Mal Einblicke in DALL-E 2, das neue Bild-generierende KI-Modell des Unternehmens. Seitdem läuft ein geschlossener Beta-Test mit beeindruckenden Ergebnissen. Sie werfen Fragen über die Rolle von DALL-E 2 für Zukunft von kreativer Arbeit auf oder lassen Fotografen den Tod der Fotografie befürchten.
Ein zentrales Ziel der geschlossenen Beta-Phase ist, die Künstliche Intelligenz für den Einsatz als frei verfügbares Produkt vorzubereiten. Dafür möchte OpenAI sicherstellen, dass DALL-E 2 insbesondere keine gewalttätigen oder sexuellen Inhalte generiert. Bisher zeigt sich DALL-E 2 ziemlich regelkonform.
Das Unternehmen hat dafür eine Reihe von Maßnahmen ergriffen wie Input- und Upload-Filter für die Eingabemaske des Systems, Einschränkungen der Anzahl gleichzeitig generierbarer Bilder, eine umfassende Content-Policy und eine aktive Kontrolle generierter Inhalte inklusive menschlicher Reviews von fragwürdigen Inhalten.
OpenAI filtert die Trainingsdaten automatisiert
Abseits dieser Maßnahmen konzentriert sich OpenAI auf eine Abmilderung potenziell gefährlicher Inhalte im Trainingsdatensatz. Für das Training von DALL-E 2 sammelte OpenAI hunderte von Millionen Bilder und zugehörige Beschriftungen im Internet. Im automatisch gesammelten Datensatz fanden sich daher zahlreiche Bilder mit unerwünschten Inhalten.
Um diese Inhalte zu identifizieren und zu entfernen, nutzt OpenAI einen halb-automatisierten Prozess: Mit einigen hundert per Hand als problematisch eingestuften Bildern wird ein neuronales Netzwerk zur Bildklassifizierung trainiert. Ein weiterer Algorithmus nutzt diesen Klassifizierer dann, um im Hauptdatensatz einige Bilder zu finden, die die Leistung des Klassifizierers verbessern könnten. Diese Bilder werden anschließend von Menschen bearbeitet und - sofern passend - für das weitere Training des Klassifizierers genutzt. Dieser Prozess wird für mehrere spezialisierte Klassifizierer durchgeführt.
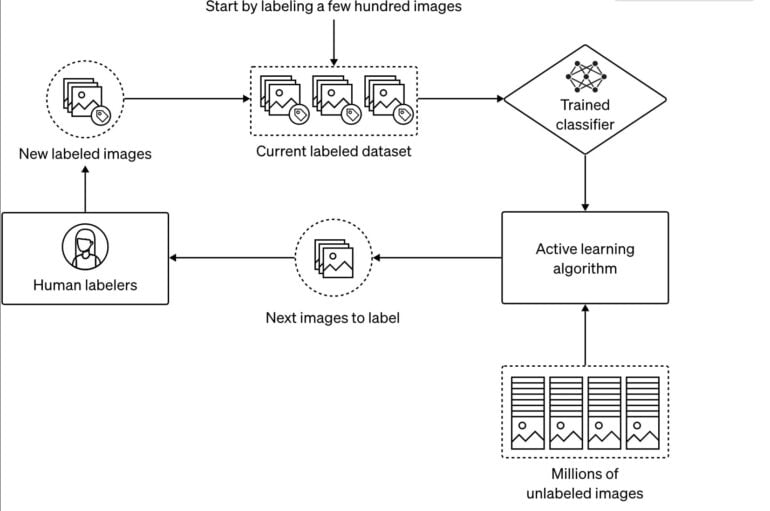
Der trainierte Klassifizierer kann anschließend problematische Bilder automatisch aus hunderten Millionen Bildern filtern. Dabei habe das Herausfiltern von problematischen Daten den Vorrang vor dem Erhalt unproblematischer Daten, schreibt OpenAI. Es sei deutlich leichter, ein Modell später mit weiteren Daten zu verfeinern, als das Modell dazu zu bringen, etwas bereits gelerntes zu vergessen.
Durch den sehr vorsichtigen Filterprozess seien etwa fünf Prozent des gesamten Trainingsdatensatzes ausgeschieden, darunter auch zahlreiche Bilder, die keine problematischen Inhalte zeigen, so das Unternehmen. Bessere Klassifizierer könnten in Zukunft einen Teil dieser verlorenen Daten wiedergewinnen und die Leistung von DALL-E 2 noch verbessern.
Um die Effizienz ihres Ansatzes zu testen, trainierte OpenAI zwei GLIDE-Modelle, eines gefiltert und eines ungefiltert. GLIDE ist ein direkter Vorgänger von DALL-E 2. Wie erwartet, generierte das gefilterte Modell deutlich weniger sexuelle und gewalttätige Inhalte.

Datenfilter erhöht Bias im KI-Modell
Der erfolgreiche Filterprozess hat jedoch einen unerwarteten Nebeneffekt: Er schafft oder verstärkt den Bias des Modells gegenüber bestimmten demografischen Gruppen. Dieser Bias sei auch so eine große Herausforderung, doch der eigentlich positive Filterprozess verstärke das Problem noch einmal, so OpenAI.
Als Beispiel nennt das Unternehmen die Eingabe "ein CEO": Das ungefilterte Modell neige dazu, mehr Bilder von Männern als Frauen zu erzeugen - ein Großteil dieses Bias sei auf die Trainingsdaten zurückzuführen. Doch beim gefilterten Modell sei dieser Effekt noch verstärkt worden - es zeigte fast ausschließlich Bilder von Männern. Im Vergleich zum ungefilterten Modell sei die Frequenz des Wortes "Frau" im Datensatz um 14 Prozent reduziert, die für "Mann" lediglich sechs Prozent.
Das habe mutmaßlich zwei Ursachen: Trotz ungefähr gleicher Repräsentation von Männern und Frauen im originalen Datensatz enthalte dieser womöglich Frauen häufiger in sexualisierten Kontexten. Die Klassifizierer entfernen daher mehr Bilder von Frauen und verstärken so das Ungleichgewicht. Zusätzlich könnten die Klassifizierer selbst durch bestimmte Klassendefinitionen oder Implementierung verzerrt sein und mehr Bilder von Frauen entfernen.
OpenAI fixt Bias mit Umgewichtung der Trainingsdaten
Das Team von OpenAI konnte diesen Effekt allerdings signifikant reduzieren: Die noch vorhandenen Trainingsdaten für das Modell wurden neu gewichtet, indem etwa die seltener vorkommenden Bilder von Frauen stärkeren Einfluss auf das Training des Modells haben. Für getestete Wörter wie "Frau" und "Mann" seien die Frequenz-Werte etwa auf ein und minus ein Prozent statt den 14 und sechs Prozent gesunken.

In einem Blog-Beitrag zeigt OpenAI zudem, dass Modelle wie GLIDE und DALL-E 2 manchmal auswendig lernen, also Trainingsbilder reproduzieren, statt neue Bilder zu erstellen. Das Unternehmen identifizierte als Ursache Bilder, die häufig im Trainingsdatensatz wiederholt werden. Das Problem lasse sich durch das Entfernen visuell ähnlicher Bilder entfernen.
Als Nächstes möchte OpenAI die Filter für das Training weiter verbessern, den Bias in DALL-E 2 weiter bekämpfen und den beobachteten Effekt des Auswendiglernens besser verstehen.




