Die Programmier-KI "Copilot" von OpenAI, Github und Microsoft könnte Lizenzrechte im großen Stil verletzen. Oder auch nicht. Github-Chef Nat Friedman erwartet für die kommenden Jahre eine "interessante politische Diskussion" rund um generative KI und das Urheberrecht.
Wenn Menschen etwas Neues erschaffen, sei es in der Kunst, der Literatur oder eben bei der Entwicklung neuer Software, dann befassen sie sich zuvor gemeinhin mit dem, was Menschen ähnlicher Profession zuvor in ihrem Bereich getan haben, und lassen Erkenntnisse daraus in ihr eigenes Werk einfließen. Ob das bewusst oder unbewusst passiert, in jedem Fall ist dieser Prozess unvermeidlich, wenn man Teil dieser Welt ist.
Die Antwort auf die Frage, wie neu ein Ergebnis ist, also wie originell, bildet dann die Grundlage für das Urheberrecht, was letztlich zwischen plumper Kopie und legitimer Inspiration entscheiden muss.
Jetzt und in den kommenden Jahren stellt sich die Frage, wie wir mit Maschinen umgehen, die das Wissen anderer Menschen verwenden, um neue Ergebnisse und Werte zu schaffen. Das zeigt die Diskussion rund um Githubs Co-Coding-KI "Copilot".
Codex profitiert von menschlichem Know-how
OpenAIs KI-Modell Codex, das Githubs Copilot antreibt, wurde mit Milliarden öffentlich verfügbaren Code-Beispielen trainiert. Nur auf Basis dieser menschlichen Beispiele kann Codex bestehenden Code syntaktisch korrekt ergänzen oder neue Code-Passagen generieren.
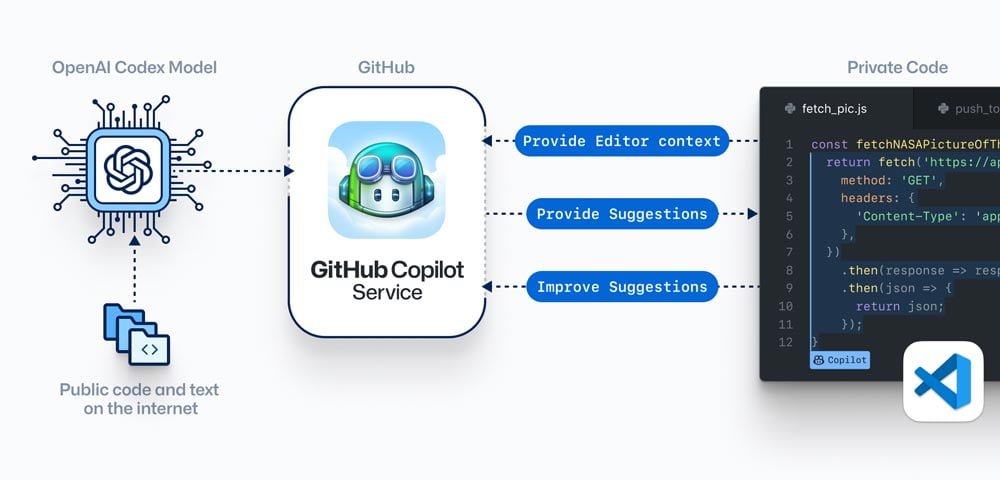
Das bedeutet auch: In jedem Code-Schnipsel, den Codex ausgibt, steckt die Denkarbeit vieler menschlicher Entwickler.
Ist das ein Problem? Menschen lernen, wie eingangs beschrieben, schließlich auch an den Beispielen anderer Menschen, ohne dass daraus automatisch eine Copyright-Verletzung entspringt. Warum sollte eine lernende Maschine anders behandelt werden als ein lernender Mensch?
Auf diese Argumentation zieht sich OpenAI im Kern zurück: Das KI-Training mit öffentlich verfügbaren Daten gelte in der KI-Branche als "Fair Use", also eine Datenverarbeitung zugunsten "öffentlicher Bildung und der Anregung geistiger Produktionen" ohne explizite Genehmigung des Urheberrechtsinhabers.
In einer Erklärung gegenüber dem US-Patentamt (USPTO) bezüglich Fair Use hebt OpenAI speziell den transformativen Charakter des maschinellen Lernens hervor (Seite 4), sodass durch die Verarbeitung öffentlicher Daten ein Mehrwert für die Gesellschaft entstehen kann. Die Ausgabe des KI-Modells gehöre der Person, die sie ausgelöst hat - wie bei einem Compiler, der die Anweisungen des Programmierers in Maschinensprache übersetzt, sagt Github-Chef Nat Friedman.
Entwickler kritisieren Copilot und OpenAI Codex wegen potenzieller Urheberrechtsverletzung
Obwohl OpenAI und Github das Thema Copyright direkt bei der Codex-Veröffentlichung mitdachten und adressierten, handelten sich die Unternehmen teils harsche Kritik ein. Auch weil Codex zum Teil eindeutige Copyright-Verletzungen begeht, wenn das KI-System persönliche Details oder ganze Code-Passagen unverändert aus dem Trainingsmaterial übernimmt.
Github räumt im FAQ zu Copilot ein, dass nur in ungefähr 0,1 Prozent der Fälle Codex-Code exakt der menschlichen Vorlage aus dem Trainingsmaterial entspricht. Typischerweise passiere das, wenn Code-Zeilen sehr weit verbreitet seien oder wenn die Anfrage des Entwicklers an das System zu wenig Kontext biete.
Im folgenden Beispiel zitiert Codex Original-Code aus dem PC-Spiel Quake III Arena (1999) - inklusive der Originalkommentare des bekannten Entwicklers John Carmack.
I don't want to say anything but that's not the right license Mr Copilot. pic.twitter.com/hs8JRVQ7xJ
— Armin Ronacher (@mitsuhiko) July 2, 2021
Github arbeitet an einem System, das diese Originalkopien zukünftig in Echtzeit erkennt und Entwickler über die Herkunft des Codes informiert.
Ein weiterer Vorwurf lautet, dass sich OpenAI an der intellektuellen Leistung menschlicher Entwickler bereichern wolle: OpenAI nehme Entwickler-Code und verkaufe ihn anschließend an diese zurück - in der Form eines KI-Generators.
Hi. I know you’re excited about copilot.
GitHub scraped your code. And they plan to charge you for copilot after you help train it further.
It’s truly disappointing to watch people cheer at having their work and time exploited by a company worth billions.
— Brian P. Hogan (@bphogan) July 2, 2021
Ein Entwickler hinterfragt, ob Codex letztlich nur ein System sei, um frei verfügbaren Open-Source-Code sicher in Code für kommerzielle Produkte zu überführen. Er nennt diesen Vorgang "Code-Wäsche".
github copilot has, by their own admission, been trained on mountains of gpl code, so i'm unclear on how it's not a form of laundering open source code into commercial works. the handwave of "it usually doesn't reproduce exact chunks" is not very satisfying pic.twitter.com/IzqtK2kGGo
— eevee (@eevee) June 30, 2021
Generative KI und Urheberrecht: Vorerst ein rechtsfreier Raum
Die Debatte zu Copilot macht vor allem eines deutlich: Die rechtlichen Aspekte generativer KI-Systeme sind lange nicht geklärt. Das gilt für Codex ebenso wie für OpenAIs GPT-3 und zahlreiche andere KI-Systeme, die etwa die Stimmen menschlicher Sprecher klonen oder Gesichter von Schauspielern zwischen Filmen kopieren.
Hinzu kommt, dass die Fair Use-Regelung, auf die sich OpenAI bezieht, vornehmlich in den USA gilt, das KI-System Codex aber mit Daten aus aller Welt trainiert wurde und international im Einsatz ist.
Der Lizenzrecht-Anwalt Luis Villa, der unter anderem Wikimedia und Mozilla beriet, urteilt bei Twitter, dass es sich bei generativer KI um "ein komplett neues Recht" handele, das auf Vergleichen mit alten Technologien beruhe und das noch nicht vor Gericht getestet worden sei.
Die aktuellen Diskussionen seien hypothetisch, auch weil KI-Inhalte bislang wenig ökonomischen Nutzen geschaffen hätten. Er sehe jedoch ein geringes Risiko, dass Codex Urheberrecht verletzt und würde seinen Klienten dazu raten, das System ohne Sorge zu nutzen.
There is an observable trend in US law, based on fair use and older notions in US copyright law of the need for creativity, that judges give a looooot of leeway to “machines that read”. Copilot fits pretty squarely in that tradition. https://t.co/xp72BMxaMx
— Luis Villa (@luis_in_brief) June 30, 2021
Letztlich fordert auch OpenAI eine Klärung durch Gesetzgeber, selbst wenn sich das Unternehmen seiner Fair Use-Argumentation sicher ist: "Dennoch verursacht die Rechtsunsicherheit über die urheberrechtlichen Auswirkungen des Trainings von KI-Systemen für KI-Entwickler erhebliche Kosten und sollte daher verbindlich geklärt werden."
US-Politiker müssten zulassen, dass "die jüngsten dramatischen Innovationen" im Bereich Künstliche Intelligenz weiterhin möglich seien "ohne unangemessene Belastungen durch das Urheberrechtssystem", so OpenAI.
Github-Chef Nat Friedman, der beim KI-Datentraining ebenfalls für Fair Use plädiert, erwartet eine lange Debatte: "Wir erwarten, dass IP (geistiges Eigentum) und KI in den kommenden Jahren zu einer interessanten politischen Diskussion weltweit führen werden, und wir sind bereit, uns daran zu beteiligen!"
Die ehemalige EU-Abgeordnete und Piratenpartei-Politikerin Julia Reda, die sich unter anderem mit dem Thema Open Science befasst, warnt bei Heise vor einer restriktiven Urheberrechtspolitik zu generativer KI, da diese "fatale Folgen für den freien Zugang zu Wissen und Kultur" haben könne:
"Was würde ein Musiklabel daran hindern, eine KI mit ihrem Musikkatalog zu trainieren, um automatisch alle erdenklichen Melodien zu generieren und deren Nutzung durch Dritte zu untersagen? Was würde Verlage stoppen, Millionen Sätze zu erzeugen, und auf diesem Wege die Sprache zu privatisieren?"
Titelbild: Github





