
OpenAIs neues KI-Modell GLIDE generiert Bilder nach Texteingabe. Die Ergebnisse sind besser als die anderer bekannter KI-Modelle - auch als die von OpenAIs DALL-E.
Anfang des Jahres stellte das KI-Unternehmen OpenAI das multimodale KI-Modell DALL-E vor. Die Künstliche Intelligenz ist mit Bild- und Textdaten trainiert und kann daher zu einer Texteingabe passende Bilder generieren.
Die generierten Bilder lässt OpenAI anschließend von dem ebenfalls multimodalen KI-Modell CLIP nach Qualität sortieren. OpenAI veröffentlichte abgespeckte Versionen von CLIP, bietet aber bisher keinen Zugang zu DALL-E.
Im Laufe des Jahres nutzten KI-Forschende CLIP in Kombination mit der Deepfake-Technik GANs (Generative Adversarial Network), um beeindruckende KI-Systeme zu schaffen, die mit Texteingaben Bilder generieren oder modifizieren.
Diffusion Models schlagen GANs
Im Februar veröffentlichte OpenAI eine Arbeit, in der das Team zum ersten Mal mit einer neuen Netzwerkarchitektur hervorragende Ergebnisse bei der Bildgenerierung erreichte. Statt der typischen GANs verwendete OpenAI sogenannte Diffusion Models.
Diese KI-Modelle fügen Bildern während ihres Trainings schrittweise Rauschen hinzu und lernen anschließend, diesen Prozess umzukehren. Nach dem KI-Training kann ein Diffusion Model dann im Idealfall aus purem Rauschen beliebige Bilder mit im Training gesehenen Objekten generieren.
Im Mai schlugen OpenAIs Bild-Ergebnisse mit Diffusion Models dann das erste Mal die Bildqualität von GANs. In einer jetzt veröffentlichten Arbeit zeigt ein Team von OpenAI, wie ein Diffusion Model mit Textsteuerung DALL-E und andere Modelle hinter sich lässt.
KI-Bilder werden immer glaubhafter
GLIDE steht für "Guided Language to Image Diffusion for Generation and Editing" und kann, wie der Name bereits verrät, mit Diffusion Models Bilder generieren und bearbeiten allein anhand von Texteingaben.
Das KI-Modell wurde dafür mit Bildern und Bildunterschriften trainiert. Das Team experimentierte außerdem mit einer Integration von CLIP. Allerdings erzeugte die erste Variante, die selbstständig lernt, Bilder aus Texten zu generieren, bessere Ergebnisse als jene mit zusätzlicher KI-Qualitätskontrolle durch CLIP.

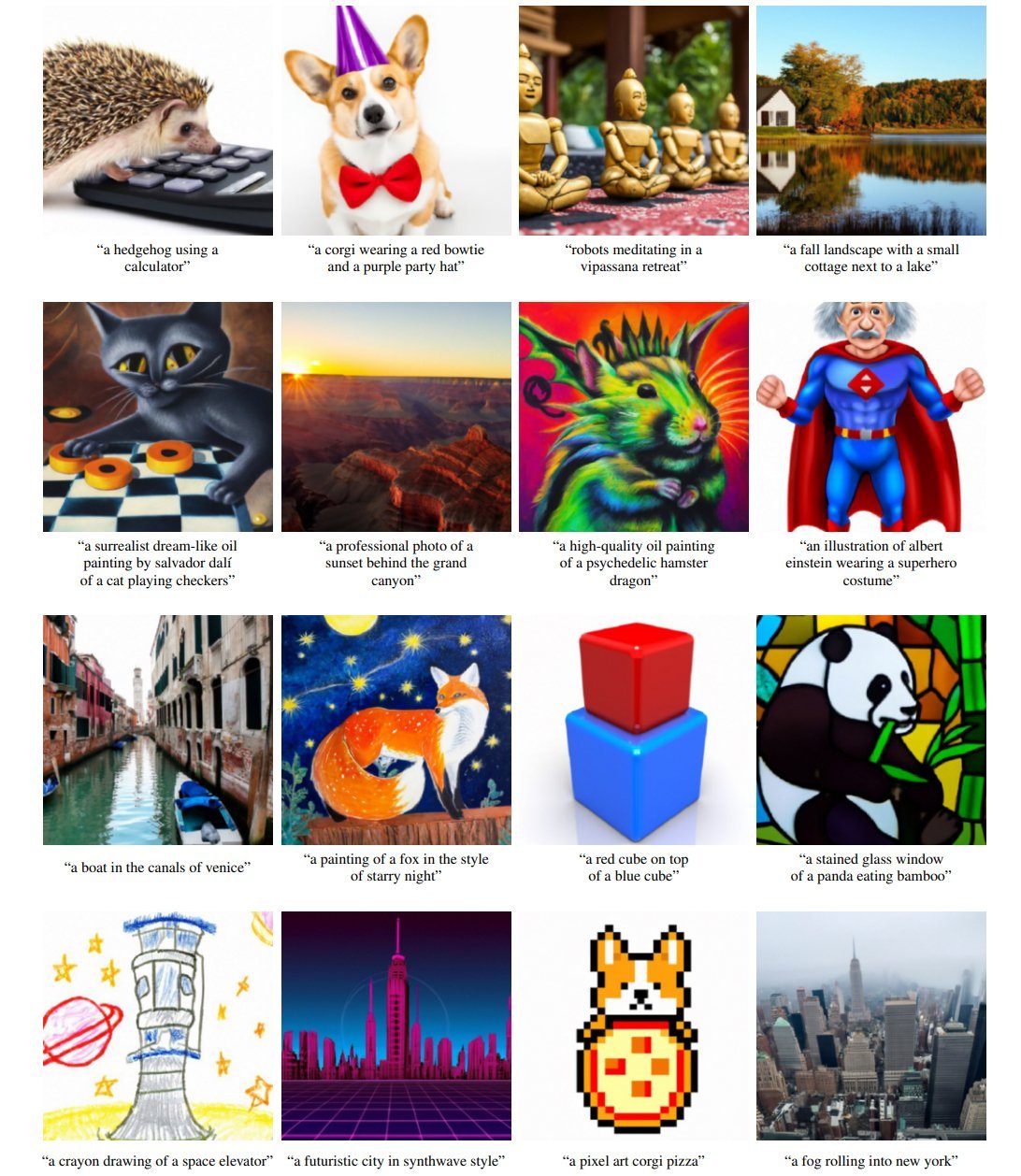
GLIDE kann zudem Bilder verändern: Nutzer:innen markieren die Stelle, die sie ändern wollen, auf dem Bild, und beschreiben die Veränderung dann per Text. GLIDE passt dann automatisch das Bild an.

Alle Bilder wurden von einem 3,5 Milliarden Parameter großen Netz in einer Auflösung von 64 mal 64 Pixel generiert und von einem 1,5 Milliarden Parameter großem Netz auf 256 mal 256 Pixel hochgerechnet. Bei einem Test bewerteten Menschen die Ergebnisse von GLIDE deutlich besser als die von DALL-E oder anderen Netze.
Für bestimmte Texteingaben liefert GLIDE keine Ergebnisse, etwa wenn ein Auto mit eckigen Rädern generiert werden soll. Das Modell ist außerdem langsamer als GAN-Alternativen und eigne sich daher nicht für Echtzeit-Anwendungen, schreiben die Forschenden.
OpenAI hält das große GLIDE-Modell vorerst zurück. Eine kleinere 300-Millionen-Parameter-Variante von GLIDE gibt es allerdings frei verfügbar. Das Team hat das veröffentlichte KI-Modell aus Sicherheitsgründen zusätzlich mit einem stark gefilterten Datensatz trainiert. Die kleine GLIDE-Variante kann etwa keine Bilder von Menschen generieren.
Weitere Informationen und die Daten gibt es im Github von GLIDE. Über ein Google Colab lässt sich GLIDE zudem testen.





