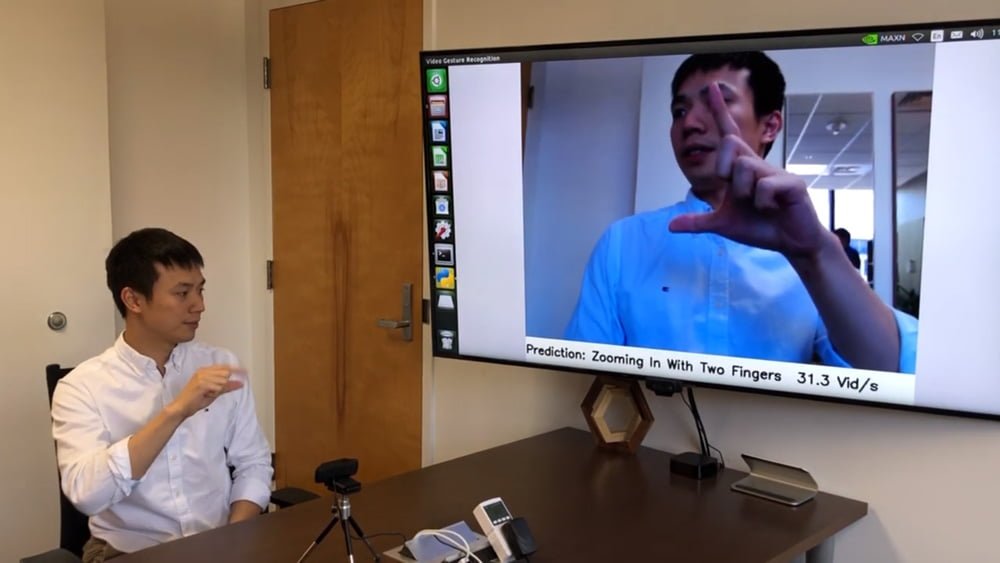
Eine neue KI-Videoanalyse von IBM läuft auch auf schwacher Hardware wie einem Smartphone. Das erlaubt etwa Echtzeit-Gestenerkennung mit günstigen Prozessoren.
Mächtige Text-KIs wie OpenAIs GPT-2 und Nvidias Megatron, Bilderkennungs-KIs, die Krebserkrankungen Jahre im Voraus analysieren, autonome Autos sehen lassen oder Gesichter scannen, sie alle haben eine Sache gemeinsam: Sie funktionieren dank riesiger Datenmengen und massig Rechenleistung.
Das hat zwei wesentliche Nachteile: Der CO2-Fußabdruck allein für das Training der KI-Systeme ist groß. Hinzu kommt, dass solche Riesen nur in der Cloud laufen. Auf dem Weg zu autonomen Drohnen, smarten Assistenten oder dem fahrerlosen Fahrzeug braucht es aber effiziente KIs, die mit wenig Rechenleistung, geringem Energieverbrauch und sogar ohne Internetverbindung ihre Arbeit verrichten.
Google rollt seinen effzienterten Offline-Assistenten aus
Dass das möglich ist, zeigt etwa Googles Next-Gen-Assistant, der lokal auf den neuen Pixel-Smartphones läuft. Von 100 Gigabyte reduzierte Google die Software auf 0,5 Gigabyte. Eine andere Forschergruppe schrumpfte kürzlich die Sprach-KI BERT: "DistilBERT" ist 60 Prozent kleiner, schneller und nahezu genauso leistungsstark. Die Beispiele zeigen: KI kann effizienter werden.
Nun haben Forscher des MIT-IBM Watson Forschungslabors leistungsstarke Videoanalyse-KIs auf vergleichsweise schwacher Smartphone-Hardware zum Laufen gebracht.
Das funktioniert so: Normalerweise verarbeiten Videoanalyse-KIs Bild für Bild. Dafür teilt die KI das Video zunächst in seine Einzelbilder und analysiert diese dann. Solange auf den Bildern nur Objekte erkannt werden müssen, funktioniert die Methode zuverlässig.
Doch die IBM-Forscher wollten mehr, nämlich eine KI, die nicht nur Inhalte auf einzelnen Bildern erkennt, sondern den Zusammenhang zwischen ihnen – die also das Video als solches sieht. Diese Aufgabe ist kompliziert, denn sie hat eine zeitliche Dimension: Es ist eine Sache, etwa eine Kiste zu erkennen, aber eine ganz andere, zu verstehen, ob die Kiste geöffnet oder geschlossen wird. Dafür muss die zeitliche Reihenfolge der Einzelbilder beachtet werden.
Dreimal schneller – bei geringerem Leistungsbedarf
Für dieses Video-Verständnis gibt es bereits spezialisierte Netzwerke, doch die sind rechenhungrig und brauchen viel Energie. Den IBM-Forschern ist es jetzt gelungen, eine effizientere Variante zu schaffen.
Dafür modifizieren sie eine herkömmliche Bildanalyse-KI mit einem zusätzlichen Arbeitsschritt: Bilderkennungs-KIs bestehen aus mehrschichtigen neuronalen Netzen. Diese Schichten identifizieren unterschiedliche Eigenschaften eines Bildes – etwa Ecken, Kanten, Formen, Farben und schließlich ein ganzes Objekt.

Die Modifikation der Forscher hakt sich hier ein und nimmt die erkannten Eigenschaften aus einem Bild mit in die Analyse des nächsten Bildes. So "erinnert" sich die KI an das bisher Gesehene und stellt einen Zusammenhang her.
Dieser zusätzliche Arbeitsschritt verbraucht laut der Forscher keine Rechenleistung. Dennoch sei die Videoanalyse-KI dreimal schneller als bisherige. Das ermöglicht etwa präzise Gestenerkennung auf einem Endgerät mit wenig Rechenleistung wie einem Smartphone.
Die so modifizierten Bilderkennungs-KIs könnten außerdem kostengünstiger und schneller YouTube-Videos analysieren oder in Facebook-Liveübertragungen nach verdächtigen Aktivitäten Ausschau halten.
Quelle: Arxiv



