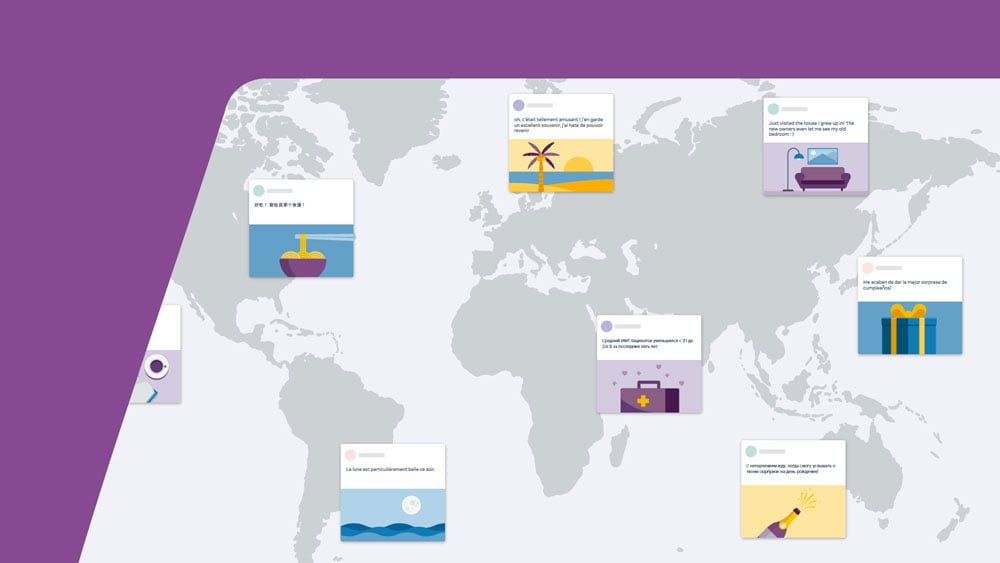
Eine neue Facebook-KI kann direkt in 100 Sprachen übersetzen, ohne den Umweg über die englische Sprache nehmen zu müssen. Das führt in einigen Sprachen zu einer deutlichen Verbesserung bei der Übersetzungsqualität.
Facebook veröffentlicht mit M2M-100 die erste Übersetzungs-KI, die zwischen jedem beliebigen Satzpaar aus 100 Sprachen übersetzt, ohne auf englische Daten angewiesen zu sein.
Bisherige KI-Modelle wie Googles M4-Modell übersetzen über Umwege: Wenn etwa Mandarin in Französisch übersetzt werden soll, lernen aktuelle KIs üblicherweise, Mandarin in Englisch und Englisch dann in Französisch zu übersetzen. Der Grund dafür ist, dass die englische Sprache weit verbreitet ist und somit besonders viele Daten für das KI-Training bietet. Auch menschliche Übersetzer arbeiten bei seltenen Sprachen über eine sogenannte "Brückensprache" wie Englisch.
Facebooks neuer KI hingegen gelingt die direkte Übersetzung von Mandarin in Französisch. Möglich ist das nicht etwa dank eines besonderen Programmierkniffs, sondern durch aufwendiges Datensammeln: Facebook ließ einen Datensatz von 7,5 Milliarden Satzpaaren aus 100 verschiedenen Sprachen erstellen.
Brückensprachen in Sprachfamilien als Trainingsbasis
Für ihre Trainingsdaten wählten die Forscher weit verbreitete Sprachen aus verschiedenen Sprachfamilien aus, für die Übersetzungen mit Evaluationsdaten existieren. Durch die Evaluationsdaten stellt Facebook sicher, dass sich die Übersetzungsleistung der KI leichter messen lässt.
Bei der Auswahl verzichteten die Forscher auf Sprachpaare, die selten übersetzt werden, etwa Isländisch zu Nepali, und suchten stattdessen nach Brückensprachen.
Um diese Brückensprachen zu finden, teilten die Forscher zuerst alle gesprochenen Sprachen in 14 Familien auf. Als Kriterien verwendeten sie etwa Geografie und kulturelle Ähnlichkeiten. Eine Sprachfamilie enthält zum Beispiel alle in Indien verbreitete Sprachen wie Bengali, Hindi, Marathi, Nepali, Tami oder Urdu.
Anschließend identifizierten die Forscher die Brückensprachen - ein bis drei Hauptsprachen in jeder Familie - und sammelten alle zu findenden Satzpaare dieser Sprachen. So kamen die 7,5 Milliarden Satzpaare zusammen.

Transformer, GPUs und blinde Flecken
Das anschließende Übersetzungstraining der KI teilten die Forscher auf hunderte Grafikkarten auf. M2M-100 ist laut Facebook mit 15 Milliarden Parametern das bisher größte komplett bilinguale KI-Modell und setzt auf die weit verbreitete Transformer-Architektur, die auch die Basis von OpenAIs Sprachmodell GPT-3 ist.
Die Transformer-Architektur ermöglicht es einer Sprach-KI, sich auf bestimmte Ausschnitte einer Eingabe zu konzentrieren und diese im Kontext der gesamten Daten zu verarbeiten – etwa Sätze innerhalb eines Artikels. Sie kann tausende Wörter gleichzeitig verarbeiten.
Facebooks Übersetzungs-KI liegt im Vergleich mit aktuellen automatischen Übersetzern im Übersetzungsbenchmark BLEU je nach Sprache zwischen 0,5 und bis zu zehn Punkten vorne und bietet so in vielen Sprachen eine bessere Übersetzungsleistung als bisherige Ansätze.
Bei seltenen Sprachen brauche es jedoch noch deutliche Verbesserungen, bevor vernünftige Übersetzungen zuverlässig automatisch erstellt werden können, schreiben die Forscher in ihrer Veröffentlichung. Beispiele seien etwa afrikanische Sprachen wie Xhosa und Zulu oder europäische Sprachen wie Katalanisch und Bretonisch. Für viele dieser Sprachen gebe es so wenige Ressourcen im Netz, dass KI-Training kaum möglich sei.
Facebook veröffentlicht M2M-100 als Open Source auf Github und will das Modell weiter verbessern.
Titelbild: Facebook | Via: Facebook





