
Nvidia stellt seine MLPerf-Ergebnisse vor und zeigt, dass die Pro-Chip-Leistung schneller ist als bei der Konkurrenz.
Nvidia ist der Platzhirsch unter den KI-Hardware-Herstellern und liefert Infrastruktur für Cloud-Systeme von Microsoft, Amazon, Dell, Inspur oder Supermicro. Kern der Systeme ist meist die Nvidia A100 GPU, der aktuell schnellste KI-Chip des Grafikkartenherstellers.
Im jüngsten MLPerf-Benchmark 1.1 treten Hardware-Hersteller und Dienstleister mit ihren KI-Systemen gegeneinander an. MLPerf wird von MLCommons geleitet und zielt auf einen transparenten Vergleich verschiedener Chip-Architekturen und Systemvarianten.
Nvidia liefert beste Pro-Chip-Leistung
Konkurrenz bekommt Nvidia im lukrativen Markt von Intels HabanaLabs, Google, Cerebras oder Graphcore. Nicht alle Hersteller nehmen bisher an MLPerf teil oder nur in bestimmten Kategorien.
Doch dort, wo direkte Vergleiche möglich sind, liefert Nvidia im Schnitt die beste Pro-Chip-Leistung. Lediglich beim KI-Training von ResNet-50 muss sich Nvidias A100 GPU Googles TPUv4 knapp geschlagen geben. Nvidias KI-Systeme sind außerdem die einzigen, die in allen acht Kategorien des Benchmarks antreten.
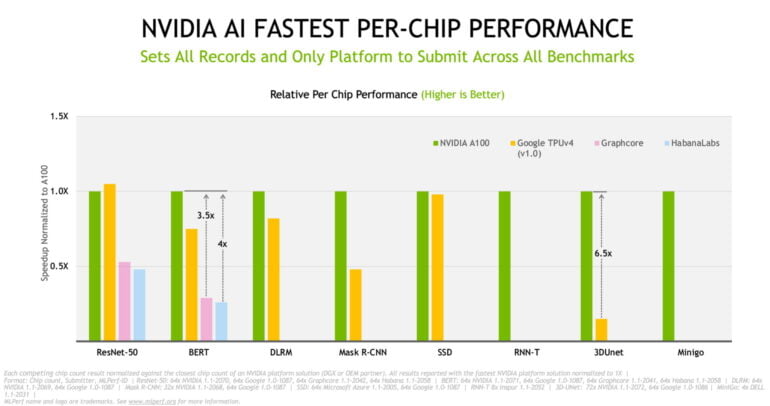
Die A100 GPUs sind auch im schnellsten System verbaut: Die Azure-Instanz NDm A100 v4 trainiert laut Nvidia KI-Systeme schneller als die Konkurrenz und skaliert dabei auf bis zu 2.048 A100 GPUs. Dank neuem Chip und verbesserter Architektur habe Nvidia die KI-Leistung so in den letzten drei Jahren um das 20-fache gesteigert.
Das britische Unternehmen Graphcore nimmt ebenfalls seit Mitte des Jahres am MLPerf teil. Jüngst verkündete Graphcore dann, die eigene Hardware habe das erste Mal Nvidia geschlagen. Laut Graphcore benötigt das KI-System IPU-POD16 mit 16 Mk2 GC200-Chips 28,3 Minuten, um das Bildanalyse-Netz ResNet-50 zu trainieren, Nvidias DGX A100 mit acht A100 GPUs dagegen 29,1 Minuten. Graphcores System hat knapp 60 Sekunden Vorsprung. Wie passt das zusammen? Alles eine Frage der Perspektive.
Nvidia kritisiert Graphcores Aussagen
Graphcore vergleicht ein 16-Chip-System mit Nvidias 8-Chip-System. Für Nvidia ist das ein Äpfel-Birnen-Vergleich: "MLPerf wurde entwickelt, um die Leistung beim Training einer Reihe von Netzwerken zu messen, die für eine Vielzahl von ML-Anwendungsfällen verwendet werden. Durch den Vergleich der Systemleistung im gleichen Maßstab können die Benutzer die relative Leistung der einzelnen Chips verstehen", so Nvidia in einer Erklärung.
"Ähnlich wie man die Leistung einer Fußballmannschaft mit 22 Spielern nicht mit der einer Mannschaft mit 11 Spielern vergleichen würde, sollte man auch nicht die Leistung eines Computersystems mit doppelt so vielen Prozessoren wie das andere vergleichen und den Sieg für sich beanspruchen."

Nvidia vergleicht daher Grapchores IPU-POD64 mit 64 Chips mit der Leistung eines 64-Chip-Systems von Nvidia. Für das Training von ResNet-50 benötigt Nvidia dann 4,53 Minuten, Graphcore dagegen 8,5 Minuten. Bei BERT fällt Graphcore mit 10,6 Minuten noch deutlicher hinter Nvidia zurück, das nur 3,04 Minuten benötigt.
Künstliche Intelligenz sei außerdem ein sich schnell entwickelnder Bereich, in dem Netzwerkarchitekturen regelmäßig ausgetauscht würden. Ein KI-System müsse daher vielseitig sein und gute Performance in allen Benchmarks zeigen, betont Nvidia.
KI-Training: Wo Geld (k)eine Rolle spielt
Graphcore sieht dagegen den Leistungsvergleich von KI-Systemen nach Anzahl der Chips pro Box nicht als guten Maßstab. Unterschiedliche Hersteller verfolgten teils sehr unterschiedliche Herangehensweisen bei ihrer Prozessorarchitektur und den Produktionsmethoden.
So sei die Verteilung der Rechenleistung auf mehrere kostengünstigere Prozessoren ein bewusster Teil des Systemdesigns von Graphcore. Dazu zähle auch der Verzicht auf teures High Bandwidth Memory (HBM), ein grundlegender Bestandteil von GPU-Systemen von Nvidia.
"Bei der Präsentation unserer MLPerf-Ergebnisse war uns immer klar, dass wir einen für Kunden aussagekräftigen Vergleich präsentieren müssen. Unser IPU-POD16 hat eine vergleichbare Größe und einen ähnlichen Stromverbrauch wie der DGX-A100 640 GB. Auf der Kostenseite sind wir bei diesem Vergleich sehr großzügig gewesen: Ein Graphcore IPU-POD16 kostet rund 150.000 US-Dollar UVP, während ein NVIDIA DGX-A100 640 GB eine UVP von rund 300.000 US-Dollar hat", so Andreas Scheffer, Territory Manager Central Europe & Automotive EMEA bei Graphcore.
Der Kostenvergleich wurde bereits Mitte des Jahres beim ersten MLPerf-Durchgang Graphcores angeführt und von Nvidia und unabhängigen Experten kritisiert. Das Fachmagazin ServeTheHome schätzte den tatsächlich gezahlten Preis für Serverbetreiber auf 130.000 bis 180.000 US-Dollar pro Nvidia-System.
Welche Perspektive man nun auch einnimmt - am Ende scheint es, dass vor allem die Vielseitigkeit der Nvidia-Systeme ein wichtiges Alleinstellungsmerkmal ist. Um wirklich mit Nvidia mitzuhalten, muss Graphcore die Unterstützung für weitere KI-Modelle ausbauen.




