
Googles neueste Bild-KI Parti generiert Bilder aus besonders umfangreichen Beschreibungen. Dadurch lassen sich die Ergebnisse noch genauer steuern.
Kürzlich stellte Google die Bild-KI Imagen vor, die mit einer ähnlichen Architektur (Diffusion) wie Open AIs DALL-E 2 Bilder generiert, aber für den Input ein großes KI-Sprachmodell verwendet - und dank dessen höherem Sprachverständnis bessere Bild-Ergebnisse aus Textbeschreibungen generieren kann.
Das jetzt von Google neu vorgestellte KI-Modell Parti (Pathways Autoregressive Text-to-Image) testet eine alternative Architektur (autoregressiv), die noch näher an der Funktion von großen Sprachmodellen etwa für die Übersetzung ist.
Diese Sprachmodelle sagen passende neue Wörter anhand vorheriger Wörter und im Kontext des Satzes oder Absatzes vorher. Parti wendet dieses Prinzip auf Bilder an - mit Erfolg.
Parti skaliert - und hat laut Google Weltwissen
Denn wie bei den großen Sprachmodellen zeigt sich auch bei Parti, dass die Bild-KI mit umfassenderem Training und mehr Parametern deutlich bessere Ergebnisse erzielt. Einfach gesagt: Das KI-Modell skaliert - und wie. Zudem kann es besonders lange, komplexe Texteingaben akkurat in Bilder umsetzen, was für ein noch besseres Verständnis für den Zusammenhang zwischen Sprache und Motiven spricht.
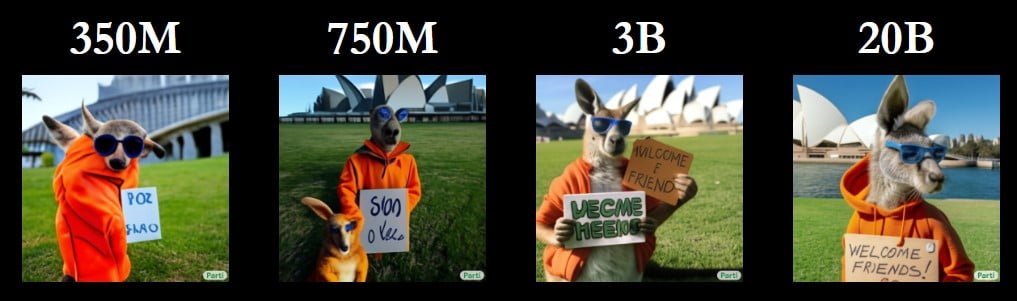
Das Bild oben zeigt den Qualitätsunterschied bei derselben Eingabeaufforderung bei vier unterschiedlich umfangreich trainierten Parti-Modellen. Das größte Modell mit 20 Milliarden Parametern generiert das fehlerfreiste Bild passend zur umfangreichen Texteingabe. Anders als DALL-E 2 kann Parti in der größten Fassung sogar Wörter richtig schreiben ("Welcome Friends").
"Das Modell 20B eignet sich besonders gut für abstrakte Aufgaben, die Weltwissen, bestimmte Perspektiven oder das Schreiben und Darstellen von Symbolen erfordern", schreibt Googles Forschungsteam.

Menschliche Tester:innen bevorzugten die Ausgaben des größten Modells im Vergleich zum Drei-Milliarden-Modell in rund 63 Prozent der Fälle. In rund 76 Prozent der Fälle sprachen sie dem 20-Milliarden-Modell die besser zum Text passende Bildausgabe zu.

Generiert werden die Bilder in der Auflösung 256 x 256 Pixel, anschließend werden sie auf 1024 x 1024 Pixel hochskaliert.

Auch Parti kann nicht zählen
Parti kann zudem fantastische Bilder generieren von Motiven, die nicht Teil des Trainingsmaterials waren und die nicht existieren. Die Forschenden sprechen der Bild-KI die Fähigkeiten zu, Weltwissen genau wiederzugeben, viele Protagonisten und Objekte mit feinen Details und Interaktionen zusammenzustellen und ein bestimmtes Bildformat sowie einen bestimmten Stil einzuhalten.

Dennoch habe das System noch zahlreiche Probleme, etwa bei der Darstellung von sinnvollen Größenverhältnissen oder bei der Unterscheidung und - wie DALL-E 2 - Zählung von Objekten innerhalb eines Bildes.
Bei der Bildeingabe "Zwei Baseballs liegen links von drei Tennisbällen" generiert das System zwei Tennisbälle und rechts davon einen weiteren Tennisball mit den Nähten eines Baseballs. Hinzu kommen technische Fehler wie auslaufende Farben.

Bedenken hat das Forschungsteam hinsichtlich der Generierung von Stereotypen, ein Problem, mit dem Imagen und DALL-E 2 ebenso zu kämpfen haben. So werden etwa Klischees von typischen Männer- und Frauenberufen verstärkt. Zudem gebe es wegen der möglichen fotorealistischen Generierung von Menschen ein zusätzliches Deepfake-Risiko. Deswegen verzichten die Forschenden zunächst auf die Veröffentlichung des Modells, des Codes und weiterer Daten. Es möchte weiter an den Problemen arbeiten.
Ist Parti Googles Bild-KI für Pathways
Interessant ist noch der Name: Das P in Parti steht für Pathways, Googles KI-Architektur der nächsten Generation, die Googles KI-Chef Jeff Dean Ende 2021 erstmals vorstellte.
Ziel von Pathways ist ein intelligentes KI-Mehrzwecksystem, das eines Tages "über Millionen Aufgaben" hinweg generalisieren kann. Dass Parti das Pathway im Namen trägt, könnte ein Hinweis sein, dass es den Bild-Part in dieser Zukunftsarchitektur übernimmt. Laut Googles Forschungsteam sind Kombinationen aus der Parti- und der Imagen-Architektur denkbar.
Das Team zeigt auf einer Webseite viele weitere interaktive Positiv- und Negativbeispiele von Parti-Bildern und erklärt den Aufbau des Systems im Detail.





