
Mit der generativen Bild-KI Imagen zeigt nach OpenAI auch Google, dass Künstliche Intelligenz glaubhafte und nützliche Bilder generieren kann.
Imagen ist Googles Antwort auf OpenAIs kürzlich vorgestellte Bild-KI DALL-E 2. Mit einem Unterschied: OpenAI enthüllte DALL-E 2 direkt als Produkt samt Beta-Test, das ab Sommer für mehr Menschen verfügbar sein soll.
Imagen schlägt laut Googles Forschenden DALL-E 2 zwar bei Präzision und Qualität, aber derzeit liegt die generative KI nur als wissenschaftliche Arbeit vor. Aus ethischen Gründen wird sich das zeitnah wohl auch nicht ändern, dazu später mehr.

Aus Text wird Bild
Imagen setzt auf ein großes, vortrainiertes Transformer-Sprachmodell (T5), das eine numerische Bildrepräsentation (Bild-Embedding) erzeugt, aus dem ein Diffusionsmodell ein Bild erstellt. Diffusionsmodelle sehen während des Trainings Bilder, die schrittweise verrauscht werden. Diesen Prozess können die Modelle nach dem Training umkehren, also aus dem Rauschen ein Bild generieren.
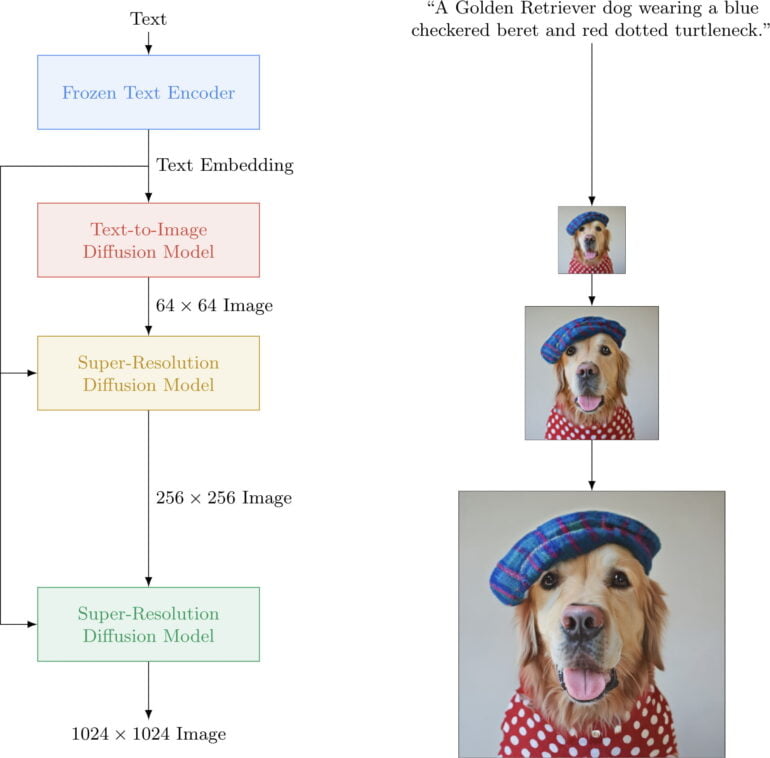
Das niedrig aufgelöste Originalbild (64 x 64) wird dann per KI-Skalierung auf bis zu 1024 x 1024 Pixel vergrößert - die gleiche Auflösung wie bei DALL-E 2. Ähnlich wie bei Nvidia DLSS, fügt die KI-Skalierung dem generierten Originalbild neue, inhaltlich passende Details hinzu, sodass es auch in der Zielauflösung eine hohe Schärfe bietet. Über diesen Hochskalierungsprozess spart Imagen viel Rechenleistung, die notwendig wäre, wenn das Modell direkt hohe Auflösungen ausgeben würde.
Imagen schneidet bei menschlicher Bewertung besser ab als DALL-E 2
Eine wesentliche Erkenntnis des Google-AI-Teams ist, dass ein großes vortrainiertes Sprachmodell "überraschend effektiv" ist für die Kodierung von Text für die anschließende Bildsynthese. Für eine realistischere Bildgenerierung habe außerdem die Vergrößerung des Sprachmodells eine größere Wirkung als ein umfassenderes Training des Diffusionsmodells, das das eigentliche Bild erstellt.
Das Team entwickelte den Benchmark "DrawBench", bei dem Menschen die Qualität eines generierten Motivs bewerten und wie gut das Motiv zum Eingabetext passt. Dabei vergleichen sie die Ausgaben mehrere Systeme parallel.
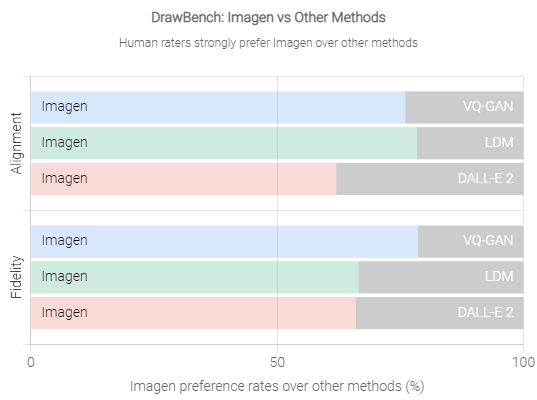
Bei diesem Test schnitt Imagen signifikant besser ab als DALL-E 2, was die Forschenden unter anderem auf das höhere Sprachverständnis des Textmodells zurückführen. Die Anweisung "A panda making latte art" könne Imagen in den meisten Fällen in das passende Motiv umsetzen: ein Panda, der Milch formvollendet in einen Kaffee kippt. DALL-E 2 erzeuge stattdessen ein Panda-Gesicht im Milchschaum.

Auch bei einem Benchmark anhand des COCO-Datensatzes (Common Object in Context) erzielte Imagen einen neuen Bestwert (7,27) und schnitt besser ab als DALL-E (17,89) und DALL-E 2 (10,39). Alle drei Bildmodelle wurden zuvor nicht mit den Coco-Daten trainiert. Nur Metas "Make-A-Scene" (7,55) agiert hier auf Augenhöhe mit Imagen, allerdings wurde Metas Bild-KI mit Coco-Daten trainiert.

Bewege dich langsam und lasse Dinge heil
Eine Veröffentlichung des Modells ist aus ethischen Gründen derzeit nicht vorgesehen, da das zugrundeliegende Textmodell "soziale Verzerrungen und Einschränkungen" enthalte, weshalb Imagen etwa "schädliche Stereotypen" erzeugen könne.
Zudem habe Imagen derzeit "erhebliche Einschränkungen" bei der Generierung von Bildern mit Menschen darauf, einschließlich "einer generellen Tendenz, Bilder von Menschen mit helleren Hauttönen zu erzeugen, und einer Tendenz, dass Bilder, die verschiedene Berufe darstellen, mit westlichen Geschlechterstereotypen übereinstimmen."
Aus diesem Grund will Google Imagen oder ähnliche Technologie "nicht ohne weitere Schutzmaßnahmen" veröffentlichen. Auch DALL-E 2 hat diese Probleme. OpenAI rollt die Bild-KI daher nur sehr langsam an circa 1000 Tester:innen pro Monat aus. Ein kürzliches Zwischenfazit nach drei Millionen generierten Bildern zeigte, dass derzeit nur ein Bruchteil der DALL-E-Motive gegen die Inhaltsrichtlinien von OpenAI verstoßen.
Jeff Dean, leitender KI-Forscher bei Google AI, sieht in KI das Potenzial, die Kreativität in der Zusammenarbeit zwischen Mensch und Computer zu fördern. Imagen sei "eine Richtung", die Google dabei verfolge. Dean teilt bei Twitter zahlreiche Bildbeispiele. Mehr Informationen und eine interaktive Demo gibt es auf der Projektseite zu Imagen.





