Googles neuer Benchmark BLEURT für Sprach-KI bewertet maschinelle Übersetzungen halbautomatisch und könnte so zu weiteren KI-Verbesserungen führen.
In der KI-Entwicklung nehmen Benchmarks eine ambivalente Rolle ein: Durch sie lassen sich KI-Systeme miteinander vergleichen und so Fortschritte messen. Aber sie dienen auch als Fixstern in der KI-Entwicklung: Häufig werden KI-Systeme für bestimmte Benchmarks entwickelt und optimiert.
Das hat zur Folge, dass ein unzureichender Benchmark nicht nur wenig bis nichts über die tatsächliche Leistungsfähigkeit eines Systems aussagt, sondern er kann zusätzlich Entwicklungsfortschritte behindern, indem er KI-Entwickler in falsche Richtung lotst.
Vor diesem Problem steht auch die Entwicklung von KI-Übersetzungen. Um deren Leistung zu bewerten, gibt es zwei Ansätze: menschliche und automatisierte Beurteilungen.
Menschen erkennen zuverlässig Feinheiten in der Sprache und sind daher der Goldstandard für die die Bewertung maschinell generierter Texte und Übersetzungen. Doch Menschen sind langsam und teuer.
Automatisierte Beurteilungen wie das häufig genutzte BLEU-Verfahren („bilingual evaluation understudy“) sind im Vergleich kostengünstig und schnell – aber weit vom menschlichen Textverständnis entfernt. Häufig sortieren sie etwa Übersetzungen aus, die zwar inhaltlich korrekt sind, aber von der Wortzahl nicht mit der im Benchmark hinterlegten Referenz übereinstimmen.

Automatische Methoden sind bisher zu ungenau
BLEU und andere automatisierte Beurteilungsalgorithmen sind daher nur bedingt geeignet, die Leistungsfähigkeit der immer besseren Übersetzungs-KIs korrekt abzubilden. Das macht es für Forscher schwierig, die Stärken und Schwächen ihrer KI-Systeme mit anderen zu vergleichen – und bremst so die Forschung aus.
Google stellt nun einen neuen Benchmark für Text-KIs vor: BLEURT (Bilingual Evaluation Understudy with Representations from Transformers) soll die Vorteile menschlicher mit denen automatisierter Beurteilungen vereinen.
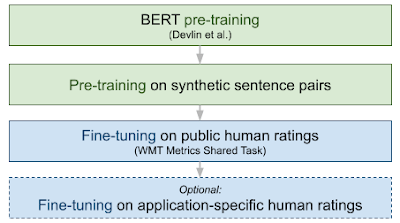
Als Grundlage für BLEURT dient ein mehrstufiges Training von Googles Sprach-KI BERT. Google zapft zuerst Wikipedia an und generiert neue Varianten von dort entnommenen Sätzen. Dafür modifiziert Google die Sätze mit BERT und anderen Methoden wie der zufälligen Löschung einzelner Wörter.


Die so entstandenen Satzpaare lässt Google anschließend von automatisierten Methoden wie BLEU oder ROUGE auf ihre Ähnlichkeit bewerten. Anschließend trainieren die Forscher die Sprach-KI BERT mit den Millionen Satzpaaren und Bewertungen.
Aus diesem Prozess aus verschiedenen automatisierten Bewertungen entspringt allerdings noch kein qualitativer Fortschritt. Er dient als Vorbereitung auf das eigentliche KI-Training mit menschlichen Bewertungen.
Googles Forscher nutzten für das abschließende Training Daten das "WMT Metric Shared Task". Insgesamt sammelten die Forscher dafür etwa 260.000 menschliche Bewertungen von Übersetzungen. Ein Training nur mit diesen Daten würde im Alleingang kein besseres System hervorbringen, da der Datensatz zu klein ist und er ausschließlich Sätze aus News-Artikeln beinhaltet.
BLEURT bis zu 50 Prozent genauer
Durch das umfassenden Vortraining mit Millionen automatisch generierter Sätze und Bewertungen kann BLEURT auch Übersetzungen anderer Texte, die keine News sind, erfolgreich bewerten. Im Vergleich zum BLEU-Algorithmus schneidet BLEURT in der Bewertungsgenauigkeit von passenden Übersetzungen fast 50 Prozent besser ab.

Dank des mehrstufigen Trainings sei BLEURT robust und liefere ein bisher nicht erreichtes Bewertungsniveau ab, das der Qualität einer rein menschlichen Bewertung näher als andere Systeme komme, schreiben die Forscher.
Das zeigt vor allem, dass der hybride Ansatz von Google funktioniert: Die Kombination aus einfach verfügbarer automatischer und aufwendigerer menschlicher Bewertung hilft, die Einschränkungen durch zu wenige KI-Trainingsdaten auszugleichen.
Quelle: Arxiv