
Facebook zeigt ein KI-System, das Objekte erkennen kann, die es noch nie gesehen hat.
Klassische Bildanalyse-KIs können Objekte nach festgelegten Kategorien erkennen, etwa Katze, Hotdog oder Elefant. Sind die Systeme gut trainiert, orientieren sie sich dabei an der Form und nicht der Textur der Objekte. Andernfalls sind sie störanfällig für Farbänderungen oder Unschärfe.
Suche ich auf Google beispielsweise Bilder von Elefanten, werden mir dank dieser KI-Bilderkennung zahlreiche Elefantenbilder angezeigt. Doch was passiert, wenn ich einen pinken Elefanten suche?
Hier kommen sogenannte multimodale Systeme ins Spiel: Sie lernen, sprachliche Konzepte mit Bilddaten zu kombinieren. Traditionell werden solche Systeme überwacht trainiert, mit einem festgelegten Vokabular an Objekten und ihrer Eigenschaften wie Farbe oder Größe.
Multimodale Systeme sind auch elementarer Bestandteil schlussfolgernder Systeme, die beispielsweise einem Roboter erlauben könnten, gezielt pinken Elefanten aus dem Weg zu gehen.
MDETR lernt von Text und Bild
Facebook-Forscher haben jetzt MDETR vorgestellt, eine Variante der Bildanalyse-KI DETR, die Facebook im Mai 2020 veröffentlichte. Wie DETR setzt auch MDETR auf eine Kombination aus Convolutional Neural Network (CNN) und Transformer-Architektur, ist jedoch mit Bild- und Textdaten trainiert worden.
Für das KI-Training nutzten die Forscher 1,3 Millionen Text-Bild-Paare, bei denen sich die Bildbeschreibungen direkt auf Inhalte des Bildes beziehen. Das CNN verarbeitet dabei die Bilder, ein großes Transformer-basiertes Sprachmodell wie RoBERTa verarbeitet die Text-Beschreibungen.
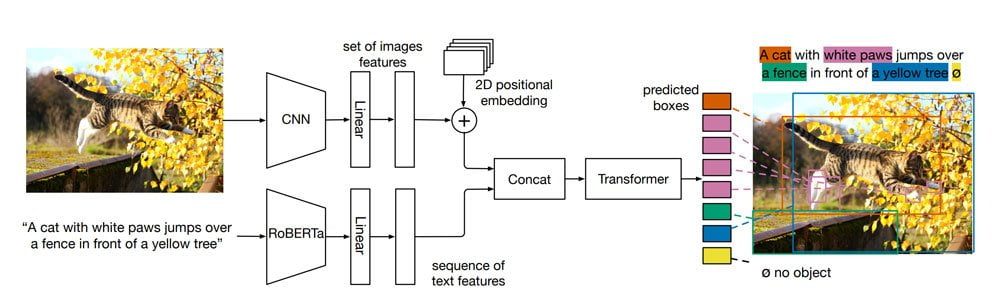
Anschließend werden beide Repräsentationen zusammengeführt und an einen weiteren Transformer gegeben. Dieser gibt anschließend zu bestimmten Begriffen passende Suchboxen für das Bild aus. Durch das Training lernt MDETR, Objekte in einem Bild ausgehend von einer Textanfrage zu identifizieren.
Als Beispiel zeigen die Forscher ein Bild von drei Elefanten, einer pink, einer blau und einer im natürlichen grau. Auf die Anfrage "ein pinker Elefant" identifiziert MDETR den pinken Elefanten mit einer 100-prozentigen Sicherheit – obwohl er während des KI-Trainings nie einen pinken Elefanten sah.


In einem anderen Beispiel identifiziert MDETR erfolgreich alle drei Personen nach folgender Beschreibung: "Die Person im grauen Hemd mit einer Uhr am Handgelenk. Die andere Person mit einem blauen Pullover. Die dritte Person mit einem grauen Mantel und Schal."
Als Beschriftung fügt die KI selbstständig und mit hoher Sicherheit "die Person", "die andere Person" und "die dritte Person" bei der jeweiligen Person ein.

Diese und andere Tests zeigen laut Facebook, dass MDETR zahlreiche visuelle und sprachliche Konzepte gelernt und verbunden hat.
OpenAIs CLIP als Inspiration
Facebooks Forscher spezialisierten MDETR außerdem auf weitere verwandte Verständnisaufgaben wie die Beantwortung von auf Bildinhalten bezogene Fragen (CLEVR). Dort erreichte MDETR Bestleistungen. Den Code für Facebooks neue Bildanalyse-KI gibt es auf Github.
Als direkte Inspiration nennen die Forscher die multimodale Bildanalyse-KI CLIP: OpenAI stellte das System Anfang des Jahres zusammen mit der Bildgenerierungs-KI DALL-E vor. Beide KI-Systeme sind wie MDETR mit Bild- und Textdaten trainiert und übertragen die Forschungserfolge von GPT-3 und anderen großen Sprach-KIs auf multimodal trainierte Transformer-basierte KI-Systeme.
Via: Arxiv





