
Deepmind erkennt Parallelen zwischen einer KI-Trainingsmethode und dem Belohnungssystem im menschlichen Gehirn.
Der Neurotransmitter Dopamin spielt eine zentrale Rolle im Belohnungssystem des menschlichen Gehirns. Neuronen, in denen Dopamin vorkommt – sogenannte dopaminerge Neuronen – sagen bei jeder Handlung eines Menschen die zu erwartende Belohnung voraus.
Tritt die Voraussage ein, wird Dopamin freigesetzt. Ist die Belohnung besser als erwartet, gibt’s mehr Dopamin. Ist sie schlechter, wird die Produktion von Dopamin unterdrückt. Die häufig als Glückshormon bezeichnete Substanz steigert Antrieb und Motivation des Menschen.
Damit erfüllt Dopamin die Rolle eines Korrektursignals: Nach und nach passt sich die Vorhersage der am Belohnungssystem beteiligten dopaminergen Neuronen der Realität an. So lernt der Mensch Verhaltensweisen, die die größte Belohnung bringen. Auch das KI-Training durch bestärkendes Lernen setzt Belohnungen als Korrektursignal ein.
Dopamin für Maschinen
Das KI-Unternehmen Deepmind arbeitet seit Jahren intensiv am bestärkenden Lernen. Mit den KI-Systemen AlphaGo, AlphaZero und Alphastar erzielte es Durchbrüche in der KI-Forschung. Grundlage dieser Erfolge ist ein von Deepmind 2017 eingeführter modifizierter Algorithmus für das bestärkende Lernen.
Dieser neue Algorithmus sagt Belohnungen anders voraus, als es zuvor üblich war: Ältere Algorithmen repräsentieren die zu erwartende Belohnung als eine einfache Zahl, die dem durchschnittlich zu erwartendem Ergebnis entspricht.
Der modifizierte Deepmind-Algorithmus stellt die zu erwartende Belohnung jedoch als eine Verteilung dar. Solche Verteilungsprognosen erfassen das volle Spektrum möglicher Belohnungen - und nicht nur den Durchschnitt.

Der Knackpunkt: Künstliche Intelligenz, die auf verteilungsbasiertes bestärkendes Lernen setzt, schneidet in spezialisierten Leistungstests besser ab als KI-Software, die nur die Durchschnittsbelohnung kennt. Noch ist nicht endgültig geklärt, weshalb das so ist – aber die verteilte Belohnung erzeugt robustere KI, die besser mit sich ändernden Umgebungen oder sich ändernden Aufgaben umgeht.
Das Gehirn ist uns einen Schritt voraus
In Kooperation mit der Universität Harvard zeigt Deepmind jetzt, dass auch das Belohnungssystem des biologischen Gehirns verteilte Gewinnprognosen für das Verhaltenstraining nutzt. Bei einem Experiment beobachteten die Forscher das Verhalten von dopaminergen Neuronen in Mäusen, während diese Aufgaben erledigten.

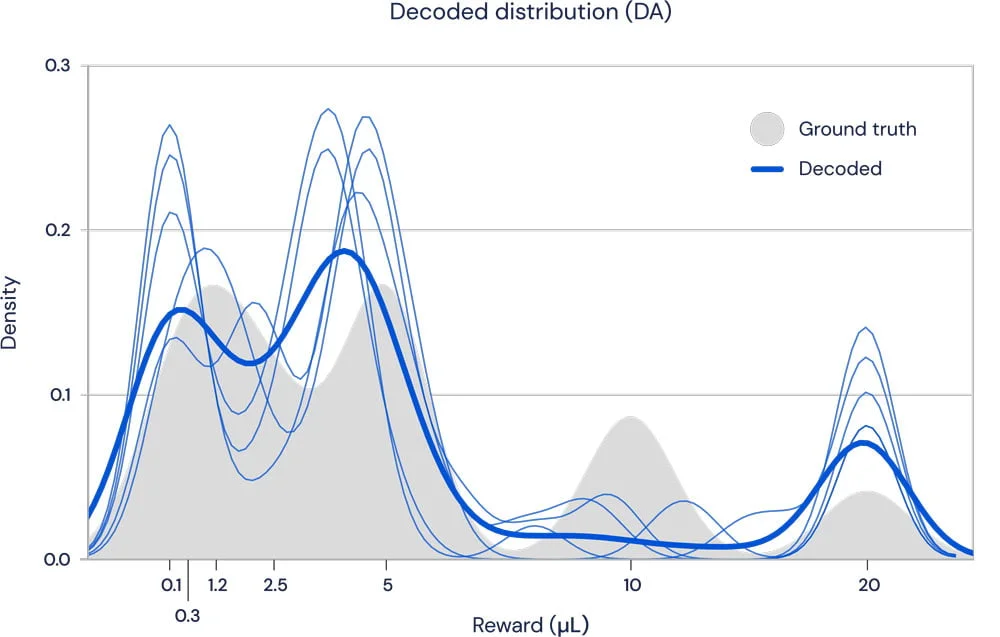
Die Forscher zeigten, dass jedes einzelne Neuron unterschiedliche Mengen Dopamin freisetzt – und damit unterschiedliche Belohnungen vorhersagt. Die Verteilung der Vorhersagen folgt dabei nahe der Verteilung der tatsächlichen Belohnungen. Für die Forscher ist das ein überzeugender Beweis, dass das Gehirn den Lernprozess durch Verteilungsprognosen steuert.
Diese Entdeckung könnte Auswirkungen auf die KI-Entwicklung und Neuroforschung haben. "Wenn das Gehirn die Methode nutzt, ist es vermutlich eine gute Idee", sagt Matt Botvinick, Leiter der Neuroforschung bei Deepmind. "Das sagt uns, dass die Technik gut mit Echtwelt-Situationen klarkommt."
Die Arbeit von Harvard und Deepmind bringt der Neuroforschung ein tieferes Verständnis des Belohnungssystems des Gehirns. Und das ist an vielen psychischen Erkrankungen beteiligt.
Quellen: Deepmind, Technology Review




