
Deepmind zeigt KI-Agenten, die Capture the Flag, Verstecken oder Fangen spielen können, obwohl sie diese Spiele noch nie gesehen haben. Möglich ist das durch umfassendes Vortraining in der Simulation.
Deepmind ist bekannt für KI-Agenten, die meisterhaft Spiele spielen: AlphaGo, AlphaZero, AlphaStar oder MuZero lernen selbstständig Spiele wie Go, Schach, Space Invaders oder Starcraft 2 und schlagen mühelos menschliche Bestleistungen.
Doch auch wenn etwa MuZero zahlreiche Spiele spielen kann, muss die Künstliche Intelligenz immer noch für jedes Spiel neu trainiert werden. Selbst die besten Deepmind-Systeme sind noch immer Spezialisten und bieten keine generalisierende Spielfähigkeit.
In einer neuen Forschungsarbeit zeigt Deepmind jetzt eine digitale Spielwiese, in der KI-Agenten tausende Mini-Spiele erleben und dabei die Fähigkeit entwickeln, vorher unbekannte, komplexe Spiele zu spielen.
Die generalisierenden KI-Agenten zeigen dank intensivem Vortraining mit vielen Spielen die Fähigkeit zum sogenannten Zero-Shot-Learning, das man bereits von großen Sprachmodellen wie GPT-3 kennt. Dank des Vortrainings mit riesigen Datenmengen kann das KI-Modell mit kleinen, spezialisierten Datensätzen auf spezifische Anwendungsfälle feinjustiert werden.
Deepminds Simulation XLand trainiert KI-Agenten mit Zufallsspielen
Die Forscher von Deepmind trainierten mehrere Generationen von KI-Agenten innerhalb einer "XLand" genannten Simulation mit dem bestärkenden Lernen: Die Spielumgebung generiert selbstständig Mini-Spiele und erlaubt daher das massenhafte Training von KI-Agenten mit unterschiedlich komplexen Aufgaben ohne menschliche Unterstützung. Einen ähnlichen Ansatz verfolgte Anfang des Jahres OpenAI mit zwei sich gegenseitig trainierenden Roboterarmen: Auch bei diesem Experiment führte das automatisierte Training zu KI-Agenten, die vorher unbekannte Aufgaben lösen konnten.
In Deepminds XLand steuern die KI-Agenten einen simplen Körper durch sich immer wieder ändernde digitale Umgebungen, die der Agent aus der Ego-Perspektive wahrnimmt. Die in der Umgebung prozedural generierten Aufgaben umfassen einfache Herausforderungen wie "Stehe neben dem lila Würfel", "Bringe den gelben Würfel auf den weißen Flur" oder auch verknüpfte Bedingungen wie "Stehe neben dem lila Würfel oder auf dem roten Flur".
Seine Aufgaben erhält der KI-Agent in Satzform, ein direktes Feedback über Erfolg oder Misserfolg folgt in definierten Zeitabständen. In vielen generierten Spielen gibt es außerdem andere KI-Agenten, die gleiche oder gegenläufige Ziele verfolgen. Interagieren kann der KI-Agent über Werkzeuge, die ihm das Aufheben oder Einfrieren von interaktiven Objekten wie etwa Kugeln, Würfeln oder Rampen erlaubt.

Xland generiert die jeweiligen Aufgaben für jeden KI-Agenten mit dem Ziel, dessen Fähigkeit zur Generalisierung auf neue Aufgaben zu maximieren. So entsteht ein automatisiertes Curriculum, das die KI-Agenten im Idealfall ständig verbessert. Um Trainings-Sackgassen zu vermeiden, setzt Deepmind außerdem auf populationsbasiertes Training, in dem aufeinander aufbauende Generationen der jeweils leistungsstärksten KI-Agenten trainiert werden.

KI-Agenten aus XLand sind besser vorbereitet
Nach fünf Generationen zeigen die KI-Agenten laut Deepmind konstante Verbesserungen im Lernen und der Leistung in vorher ungesehenen Spielen. Jeder KI-Agent hat zu diesem Zeitpunkt schon knapp 700.000 Spiele in 4.000 einzigartigen XLand-Welten gespielt und circa 200 Milliarden Trainingsschritte dank 3,4 Millionen unterschiedlicher Aufgaben hinter sich. Laut Deepmind haben die KI-Agenten mit diesem Pensum an jeder in XLand möglichen Aufgabe teilgenommen.
Die fertig trainierten KI-Agenten lassen die Deepmind-Forscher dann in neuen Spielen wie Capture the Flag, King of the Hill oder Verstecken gegeneinander antreten, die sie bis dato nicht kennen. Verschiedene Agenten zeigen laut Deepmind unterschiedliche Strategien und Fähigkeiten, generell seien jedoch heuristische und keine hochoptimierten spezialisierten Verhaltensweisen zu beobachten.
Die KI-Agenten probieren aus, experimentieren und haben damit immer wieder Erfolg. Mit extra für die jeweiligen Aufgaben trainierten KI-Agenten können die Multitalente aus XLand natürlich nicht mithalten, doch das Zero-Shot-Potenzial für die Feinjustierung zeigt, dass das umfassende KI-Training mit abwechslungsreichen Aufgaben zu stärker generalisierenden KI-Agenten geführt hat.
Im Zweifelsfall experimentieren die KI-Agenten
Eine Analyse der internen Repräsentation der KI-Agenten zeigt laut Deepmind, dass diese sich der Grundlagen ihres Körpers und des Zeitablaufs bewusst sind, sowie die übergeordneten Strukturen der Spiele verstehen, denen sie begegnen. Außerdem erkennen sie klar in ihrer Umgebung, ob sie ihr Ziel erreicht haben, noch bevor sie das Feedback über Erfolg oder Misserfolg erhalten.
In einem vorher unbekannten Puzzle soll etwa ein KI-Agent drei Objekte so sortieren, dass der schwarze Würfel nah am violetten Würfel ist, der gelbe Würfel nahe am violetten Würfel, aber der gelbe Würfel nicht in der Nähe des schwarzen Würfels.
Die Lösung: eine Linie mit dem gelben Würfel, gefolgt vom lila Würfel, gefolgt vom schwarzen Würfel. Eine vergleichbare Aufgabe hat der KI-Agent bis dahin noch nie gelöst.
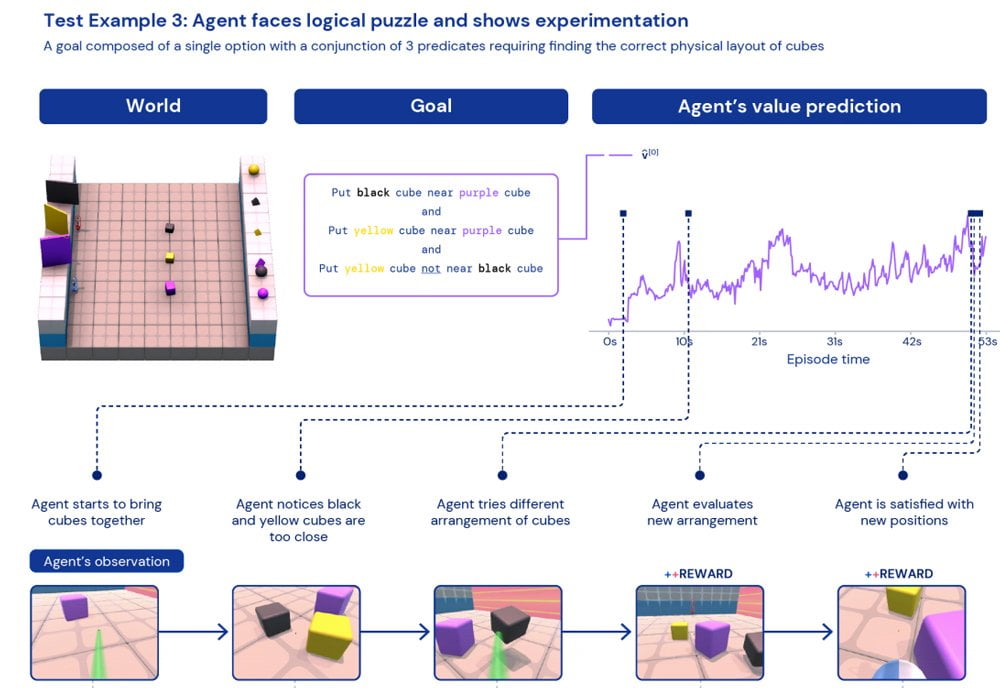
Zu Beginn bringt der KI-Agent alle drei Würfel zusammen. Nach etwa zehn Sekunden blickt der KI-Agent auf die Anordnung und sieht, dass der schwarze zu nahe am gelben Würfel steht.
Daraufhin testet der KI-Agent in den nächsten vierzig Sekunden verschiedene Anordnungen, bis die korrekte Anordnung durch Zufall entsteht. Zu diesem Zeitpunkt blickt der KI-Agent erneut auf die Anordnung und stoppt anschließend die Neujustierung der Würfelpositionen. Da der KI-Agent zu diesem Zeitpunkt noch kein Feedback über Erfolg erhalten hat, muss er rein aus der Beobachtung ableiten, dass die Anordnung der Lösung entspricht.
Das wilde Herumprobieren verschiedener Positionen bis zum zufälligen Erfolg klingt womöglich nicht sonderlich eindrucksvoll, muss laut der Deepmind-Forscher aber als ein allgemeines heuristisches Ausweichverhalten interpretiert werden.
"Wenn ein KI-Agent nicht in der Lage ist, durch Verstehen zu verallgemeinern, spielt er mit den Objekten, experimentiert und überprüft visuell, ob er die Aufgabe gelöst hat", schreiben die Forscher.
Per Feinjustierung zum enormen Leistungssprung - in nur 30 Minuten
Die KI-Agenten aus XLand können wie andere KI-Systeme, die mit vielen Daten vortrainiert wurden, mit wenigen Daten per Nachtraining auf bestimmte Aufgaben feinjustiert werden. Nach etwa 30 Minuten Nachtraining oder 100 Millionen Trainingsschritten schneiden die feinjustierten KI-Agenten in Aufgaben bis zu 340 Prozent besser ab als vor dem Nachtraining und lösen auch Aufgaben, an denen sie ohne Nachtraining scheiterten.
Die feinjustierten KI-Agenten erzielen außerdem deutlich bessere Ergebnisse als KI-Agenten ohne XLand-Vortraining, die ausschließlich 30 Minuten spezialisiert für die jeweils getestete Aufgabe trainiert wurden.
Diese Experimente zeigen laut Deepmind das große Potenzial von umfassendem KI-Vortraining in Kombination mit bestärkendem Lernen, um das KI-Modell anschließend durch Feinjustierung auf viele verschiedene nachgelagerte Zielaufgaben zu optimieren und so letztlich stärker zu generalisieren.
Das Prinzip ähnelt OpenAIs Text-KI GPT-3, die mit ausgewählten Daten für bestimmte Textaufgaben feinjustiert werden kann. Auch OpenAI ist davon überzeugt, dass das Vortraining großer KI-Modelle mit anschließender Feinjustierung ein zukunftsträchtiges Vorgehen für die Fortentwicklung Künstlicher Intelligenz ist.
Die Deepmind-Forscher hoffen, dass ihre Arbeit den Weg für anpassungsfähigere Agenten ebnet, die ihre Fähigkeiten auf komplexere Aufgaben übertragen können.
Titelbild: Deepmind | Via: Deepmind, Deepmind Blog





