
Sind riesige KI-Sprachmodelle wie GPT-3 oder PaLM untertrainiert? Deepmind zeigt, dass uns weitere Leistungssprünge erwarten könnten.
Große Sprachmodelle wie OpenAIs GPT-3, Deepminds Gopher oder jüngst das leistungsstarke PaLM von Google setzen auf viele Daten und gigantische neuronale Netze mit hunderten Milliarden Parametern. PaLM ist mit 540 Milliarden Parametern die bisher größte dicht trainierte Künstliche Intelligenz für Sprache.
Der Trend zu immer mehr Parametern entspringt der bisherigen Erkenntnis, dass die Fähigkeiten großer KI-Modelle mit ihrer Größe skalieren. Zum Teil können die riesigen Netze Aufgaben lösen, die deren Entwickler:innen nicht antizipierten.
Google PaLM etwa kann Witze erklären und verfügt über eine rudimentäre Fähigkeit zum logischen Schlussfolgern: Anhand von wenigen Beispielen in der Eingabeaufforderung ("few-shot"-Lernen) lernt das Modell, die eigene Antwort logisch zu erklären. Die Forschenden nennen diesen Vorgang "Chain-of-Thought Prompting".
Schon vor der Vorstellung von PaLM zeigten Deepmind-Forschende das Sprachmodell Chinchilla. Das Team untersuchte die Wechselwirkung von Modellgröße in Parametern und der Menge der Textdaten gemessen in der kleinsten verarbeiteten Einheit, den sogenannten Token.
Deepminds Chinchilla zeigt das Potenzial von mehr Trainingsdaten
Während in den letzten Jahren der Fokus von KI-Forschenden auf mehr Parametern für bessere Leistung lag, reduzierte Deepmind für Chinchilla die Netzwerkgröße und skalierte stattdessen die Anzahl der Trainingsdaten deutlich nach oben. Da beim KI-Training die benötigte Rechenleistung von der Modellgröße und den Trainingstoken abhängt, blieb sie auf dem Niveau des ebenfalls von Deepmind veröffentlichten Gopher.
Gopher hat 280 Milliarden Parameter und wurde mit 300 Milliarden Token trainiert. Chinchilla ist mit lediglich 70 Milliarden Parametern viermal kleiner, wurde jedoch mit etwa viermal mehr Daten trainiert - 1,3 Billionen Token.
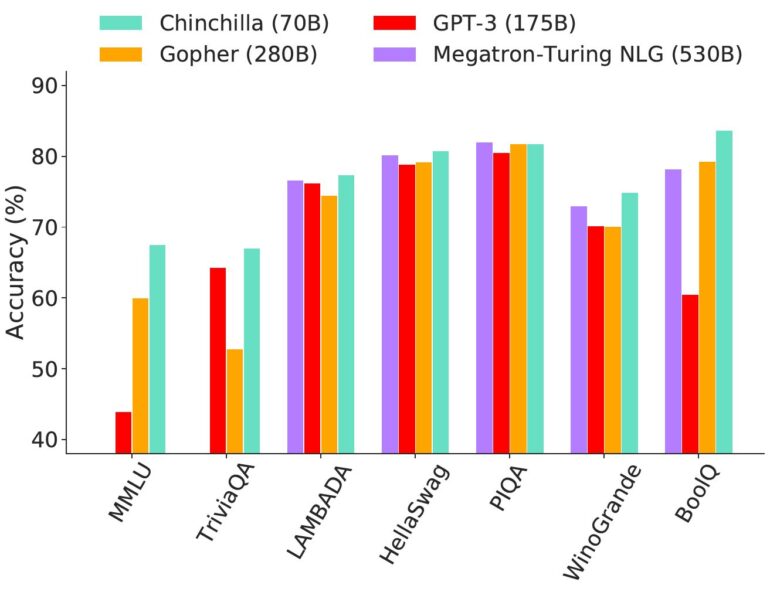
Trotz gleicher Trainingskosten für Chinchilla und Gopher zeigt der KI-Winzling bei fast jeder Sprachaufgabe eine bessere Leistung als der eigene Vorgänger. Auch andere, deutlich größere Sprachmodelle wie GPT-3 oder Nvidias und Microsofts riesiges Megatron-Turing NLG-Modell mit 530 Milliarden Parametern verweist Chinchilla auf die Plätze. Lediglich Googles PaLM mit seinen 540 Milliarden Parametern und 768 Milliarden Trainingstoken liegt vor Chinchilla.
Googles PaLM ist massiv untertrainiert
Deepminds Chinchilla zeigt, dass riesige KI-Sprachmodelle untertrainiert sind und kleinere KI-Modelle, die mit sehr vielen Daten trainiert werden, ebenfalls eine hohe Leistung erzielen können. Kleinere Modelle wie Chinchilla sind nach dem Training dazu kostengünstiger im Betrieb und können mit wenigen Zusatzdaten für spezifische Anwendungsfälle optimiert werden.

Mit diesem Ansatz könne eine 140 Milliarden "kleine" PaLM-Variante die gleiche Leistung wie die große PaLM-Version mit 540 Milliarden Parametern erzielen, so die Deepmind-Forschenden. Allerdings: Mini-PaLM würde viel mehr Trainingsdaten benötigen - satte drei Billionen Trainingstoken statt nur 768 Milliarden Token.
Oder, und diese Variante dürfte auf dem Forschungsplan stehen: Google nimmt die höheren Trainingskosten in Kauf und trainiert die größte Version von PaLM mit deutlich mehr Daten. Denn die Skalierungskurve von PaLM ähnelt der älterer Sprachmodelle wie GPT-3. Das Deepmind-Forschungsteam geht daher davon aus, dass "die Leistungsverbesserung durch Skalierung noch nicht zum Stillstand gekommen ist".
Ein so umfassendes Sprachmodell benötigt laut Deepmind jedoch mehr als zehn Billionen Token für das KI-Training - mehr als das zehnfache des bisher größten Trainingsdatensatzes für Sprachmodelle.




