
KI-Modelle werden immer größer und der Bedarf nach spezialisierter Hardware steigt. Cerebras will nun die nächste Parameter-Grenze knacken.
Cerebras kündigte seinen Wafer Scale Engine 2 Prozessor (WSE-2) bereits Ende 2020 an, im April 2021 folgten dann erste Details: Der KI-Chip wird im 7nm-Verfahren bei TSMC gefertigt, hat 850.000 für Künstliche Intelligenz optimierte Kerne und insgesamt 2,6 Billionen Transistoren.
Zum Vergleich: Die erste Generation wurde noch im 16nm-Verfahren gefertigt, hatte 400.000 KI-Kerne und 1,2 Billionen Transistoren.
Die KI-Kerne sind auf dem WSE-Wafer und kommunizieren direkt über Verbindungen im Silizium. Das macht die Wafer von Cerebras deutlich energiesparender als andere Systeme, die etwa auf Nvidia GPUs setzen.

Der 46.225 mm² große WSE-2-Chip kommt so mit 40 Gigabyte On-Chip-Speicher und einer Bandbreite von 20 Petabyte pro Sekunde. Nvidias A100-Chip ist 826 mm² groß, hat 7.350 Kerne und 40 Megabyte On-Chip-Speicher mit einer Bandbreite von 155 Gigabyte pro Sekunde.
Der WSE-2-Chip ist im CS-2-System verbaut, das in bestehende Rechenzentren integriert werden kann und etwa ein Drittel eines Server-Racks einnimmt. Ein einzelnes CS-2 soll große Cluster mit Hunderten oder Tausenden Grafikprozessoren (GPUs) ersetzen, die Dutzende von Server-Racks beanspruchen.
CS-2-System soll bis zu 120 Billionen Parameter unterstützen
Auf der Hot Chips-Konferenz gab Cerebras-Gründer und CEO Andrew Feldman nun bekannt, dass ein einzelnes CS-2-System gigantische KI-Modelle mit bis zu 120 Billionen Parametern unterstützen wird.
Das wäre ein weiter Satz nach vorne: Als aktuell größtes KI-Modell gilt Wu Dao 2.0 mit 1,75 Billionen Parametern, gefolgt von Googles Switch Transformer mit 1,6 Billionen Parametern. OpenAIs größtes GPT-3-Modell kommt auf 275 Milliarden Parameter.

Große KI-Modelle wie GPT-3 hätten bereits die maschinelle Verarbeitung natürlicher Sprache völlig verändert, so Feldman, und der Trend zu immer größeren KI-Modellen gehe weiter.

"Die Industrie ist dabei, Modelle mit einer Billion Parametern zu entwickeln, und wir erweitern diese Grenze um zwei Größenordnungen, sodass neuronale Netze auf Gehirnniveau mit 120 Billionen Parametern möglich sind", sagt Feldman.
Seinen Gehirn-Vergleich begründet Feldman damit, dass das menschliche Gehirn circa 100 Billionen Synapsen habe. Diese Zahlen und ihre Aussagekraft sind jedoch umstritten, was sicher auch Feldman weiß. Ein künstliches menschliches Gehirn wird es wohl auch mit 192 CS-2-Systemen vorerst nicht geben.
Parameter werden extern gespeichert
Möglich ist der riesige Sprung auch durch die ebenfalls vorgestellte MemoryX-Technologie, mit der Cerebras die Rechenleistung vom Modellspeicher trennt: Ein externer Speicher mit bis zu 2,4 Petabyte, bestehend aus DRAM und Flash Hybridspeicher, streamt alle Parameter des KI-Modells für das Training und die Inferenz direkt vom und zum CS-2-System.
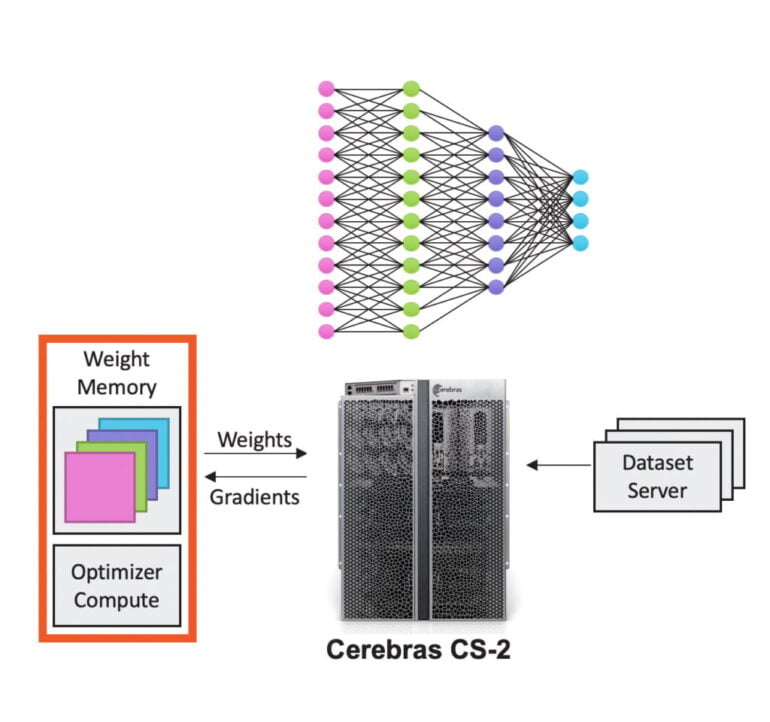
So müssen die Parameter des Netzwerks nicht auf dem WSE-2 gespeichert werden. Stattdessen streamt der Chip die für die jeweilige Rechenoperation notwendigen Informationen Schicht für Schicht.
Für mehr Rechenleistung können die bis zu 192 CS-2-Systeme mit 162 Millionen KI-Kernen verbunden werden. Dank der ebenfalls vorgestellten SwarmX-Verbindungstechnologie soll die Leistung nahezu linear skalieren. Cerebras stellte außerdem eine umfassende Unterstützung für Optimierungen (Sparsity) vor.





