Apple zeigt das KI-System GAUDI. Es kann 3D-Innenraumszenen generieren und liefert die Grundlage für eine neue Generation generativer KI.
Sogenanntes neuronales Rendering bringt Künstliche Intelligenz in die Computergrafik: KI-Forschende von Nvidia zeigen etwa, wie aus Fotos 3D-Objekte entstehen und Google setzt auf Neural Radiance Fields (NeRFs) für Immersive View oder entwickelt NeRFs für die Darstellung von Menschen.
Bisher werden NeRFs vor allem als eine Art neuronales Speichermedium für 3D-Modelle und 3D-Szenen eingesetzt, die anschließend aus verschiedenen Kameraperspektiven gerendert werden können. So entstehen die häufig gezeigten Kameradurchfahrten durch einen Raum oder um ein Objekt herum. Erste Experimente mit NeRFs für Virtual-Reality-Erfahrungen gibt es ebenfalls.
NeRFs könnten zur nächsten Stufe generativer Künstlicher Intelligenz werden
Doch was, wenn sich die Fähigkeit zur fotorealistischen Darstellung und dem Rendern aus unterschiedlichen Blickwinkeln für eine generative KI nutzen ließe? KI-Systeme wie OpenAIs DALL-E 2 oder Googles Imagen und Parti zeigen das Potenzial von steuerbarer, generativer Künstlicher Intelligenz für Bilder und Grafiken.
Einen ersten Ausblick bot Ende 2021 Googles Dream Fields, ein KI-System, das die Fähigkeit von NeRFs, 3D-Ansichten zu generieren, mit OpenAIs CLIPs Fähigkeit, Inhalte von Bildern zu bewerten, kombiniert. Das Ergebnis: Dream Fields generiert zu Textbeschreibungen passende NeRFs.
Nun zeigt Apples KI-Team das generative KI-System GAUDI, einen "neuronalen Architekt für immersive 3D-Szenenerzeugung".
Apple GAUDI ist Spezialist für Innenräume
Während sich etwa Google mit Dream Fields der Generation einzelner Objekte widmet, bleibt die Ausweitung generativer KIs auf völlig uneingeschränkte 3D-Szenen ein bislang ungelöstes Problem.
Ein Grund ist etwa die Einschränkung der möglichen Kamerapositionen: Während sich bei einem einzelnen Objekt jede mögliche sinnvolle Kameraposition auf eine Kuppel abbilden lässt, sind in 3D-Szenen die sinnvollen Kamerapositionen durch Hindernisse wie Objekte und Wände eingeschränkt. Werden diese bei der Generierung nicht beachtet, entstehen keine verwertbaren 3D-Szenen.

Apples GAUDI-Modell löst dieses Problem mit drei spezialisierten Netzwerken: Ein Decoder für Kamerapositionen trifft Vorhersagen für mögliche Kamerapositionen und stellt dabei sicher, dass die Ausgaben eine für die Architektur der 3D-Szene gültige Position ist.
Ein weiterer Decoder für die Szene sagt eine Drei-Ebenen-Darstellung voraus, die eine Art 3D-Leinwand liefert, auf der der Strahlungsfeld-Decoder das anschließende Bild unter Verwendung der volumetrischen Rendering-Gleichung zeichnet.
In Experimenten mit vier verschiedenen Datensätzen, darunter ARKitScences, einem Datensatz von Scans von Innenräumen, zeigen die Forschenden, dass GAUDI gelernte Ansichten rekonstruieren kann und dabei die Qualität existierender Ansätze erreicht.
Video: Miguel Angel Bautista via Twitter
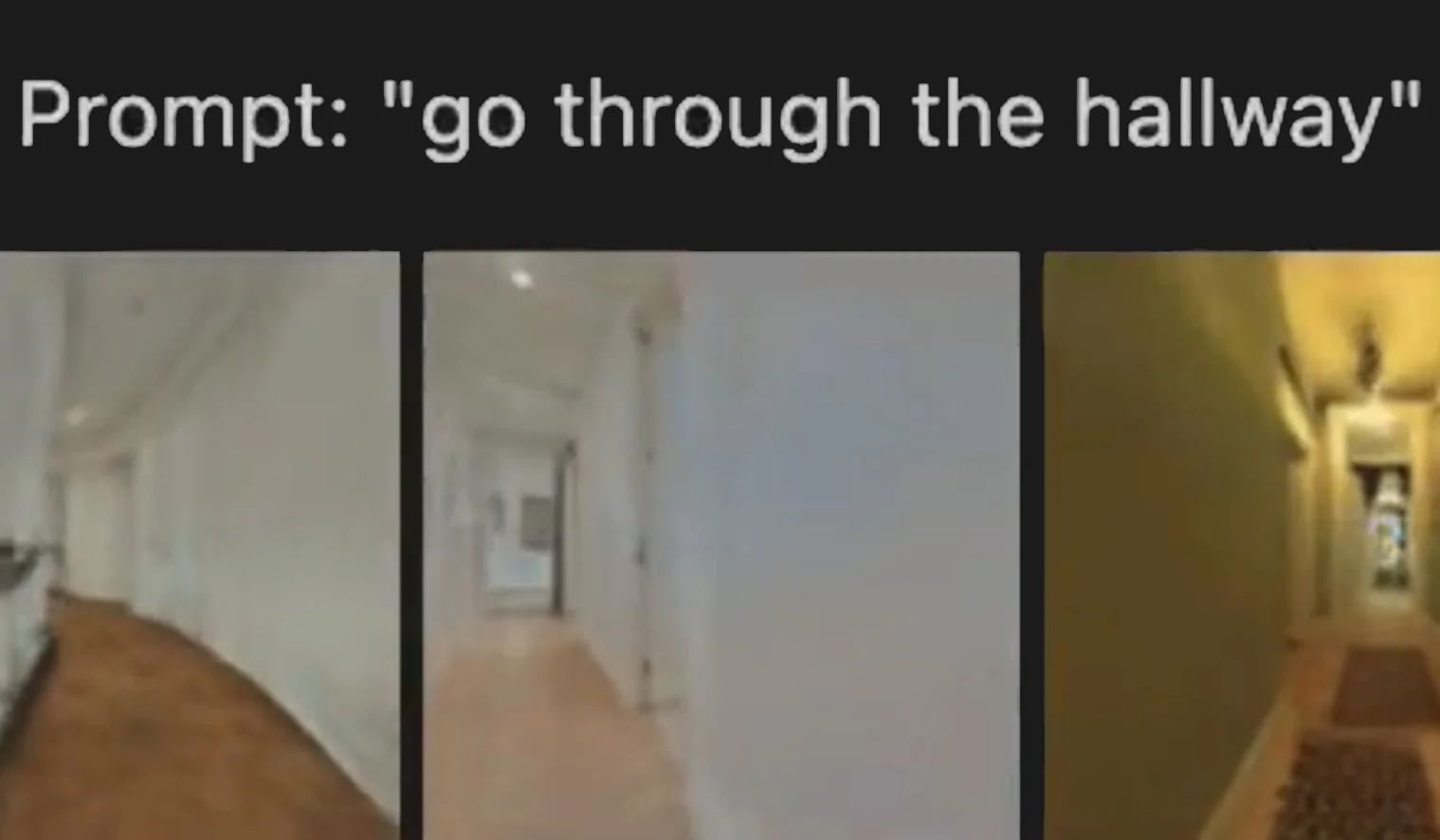
Apple zeigt zusätzlich, dass GAUDI neue Kamerafahrten durch 3D-Szenen von Innenräumen generieren kann. Dabei kann die Generierung zufällig erfolgen, von einem Ausgangsbild starten oder mit einem Text-Encoder per Texteingabe gesteuert werden - etwa "gehe durch einen Gang" oder "gehe die Treppen hinauf".
Die Qualität der von GAUDI generierten Videos ist noch gering und voller Artefakte. Doch mit dem KI-System legt Apple eine weitere Grundlage für steuerbare generative KI-Systeme, die 3D-Objekte und -Szenen rendern können.
Excited for this to be out! Introducing GAUDI: a generative model for 3D indoor scenes. We tackle the problem of learning a generative model of 3D scenes parametrized as radiance fields. This has been a great collaboration across multiple teams at @Apple. https://t.co/aJOqtzA2CI https://t.co/tSkJdXK31C pic.twitter.com/ReeXAPGg95
— Miguel Angel Bautista (@itsbautistam) July 29, 2022
Eine mögliche Anwendung: die Generierung digitaler Orte für Apples XR-Brille. Mehr über Neuronales Rendering erfahrt ihr in unserem DEEP MINDS KI Podcast mit Nvidia-Forscher Thomas Müller.





