
Deepminds Flamingo verbindet ein visuelles KI-Modell mit einem Sprachmodell. Künstliche Intelligenz soll so ein besseres visuelles Verständnis erhalten.
Große Sprachmodelle wie OpenAIs GPT-3 sind Few-Shot-Learner: Sie lernen anhand weniger Beispiele, eine Aufgabe zu erfüllen. Soll GPT-3 etwa Deutsch in Englisch übersetzen, lässt sich das Modell mit zwei bis drei Beispielübersetzungen entsprechend einstellen.
Dieses Few-Shot-Learning funktioniert, weil GPT-3 mit sehr vielen Daten vortrainiert ist. Das Nachtraining mit wenigen Beispielen ist dann vergleichbar mit einer Feinjustierung.
Deepmind zeigt jetzt Flamingo, eine Künstliche Intelligenz, die Sprachmodell und visuelles Modell miteinander verknüpft und dabei die Few-Shot-Fähigkeit auf die Bildanalyse anwendet.
Deepmind Flamingo setzt auf Chinchilla und Perceiver
Statt reiner Textbeispiele verarbeitet das visuelle Sprachmodell Flamingo in der Eingabe Beispielpaare von Bildern und Texten, etwa Fragen und erwartete Antworten zu einem Bild. Anschließend kann das Modell Fragen zu neuen Bildern oder Videos beantworten.
Als Beispiel nennt Deepmind die Identifikation und das Zählen von Tieren, etwa drei Zebras auf einem Bild. Ein traditionelles visuelles Modell, das nicht mit einem Sprachmodell verbunden ist, müsste für diese Aufgabe mit tausenden Beispielbildern neu trainiert werden. Flamingo benötigt dagegen nur einige wenige Beispielbilder mit passenden Textausgaben.
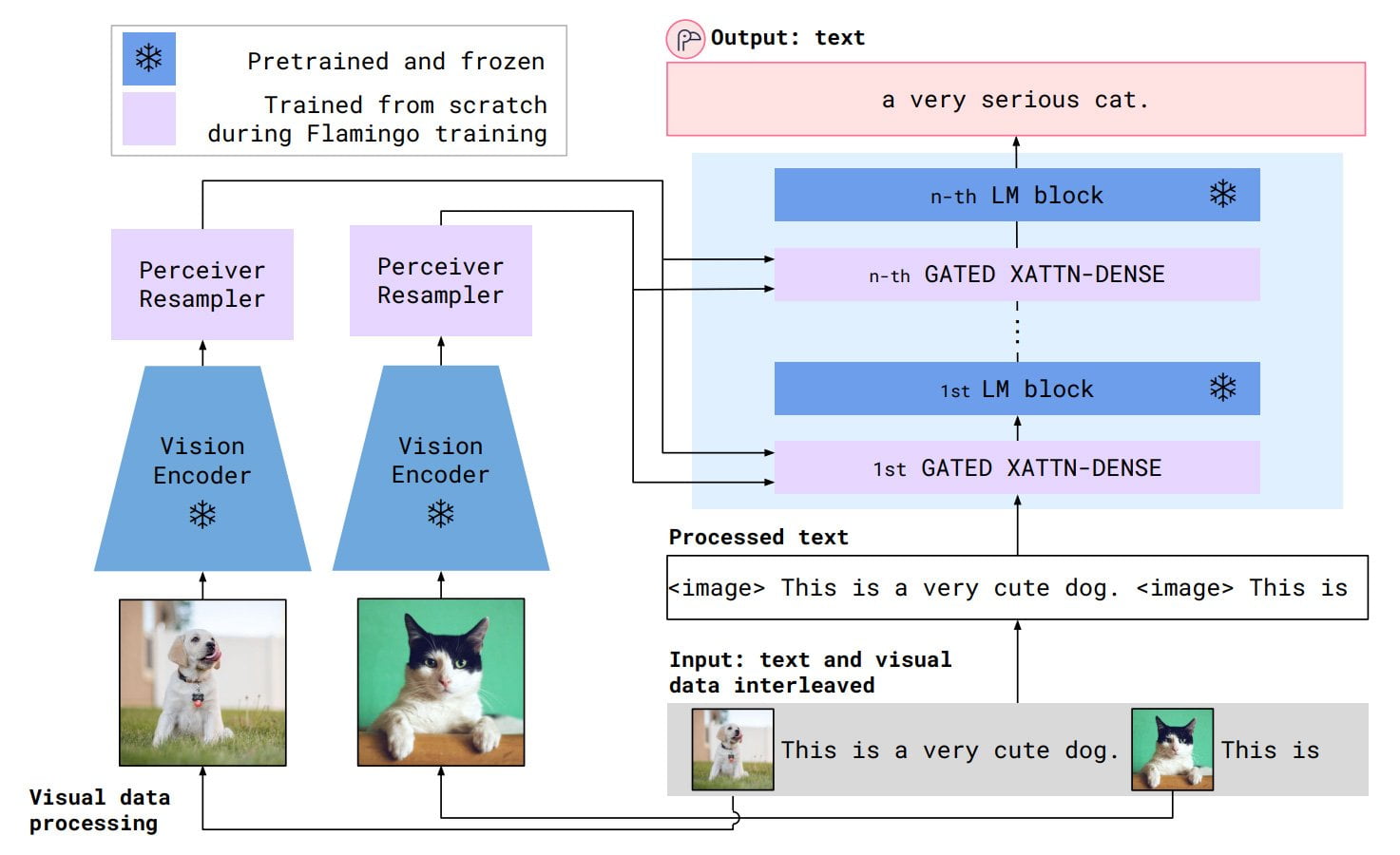
Flamingo verbindet einen mit Bildern und Text trainierten ResNet-Encoder mit einer Variante von Deepminds Sprachmodell Chinchilla. Die Verbindung wird durch Deepminds Perceiver ermöglicht, der die Ausgabe des visuellen Modells verarbeitet und an Attention-Layer vor dem Sprachmodell weitergibt.
Während des Flamingo-Trainings sind visuelles Modell und Sprachmodell eingefroren, um ihre Fähigkeit zu erhalten. Lediglich Perceiver und die Attention-Layer werden trainiert.
Flamingo zeigt einfaches Bildverständnis
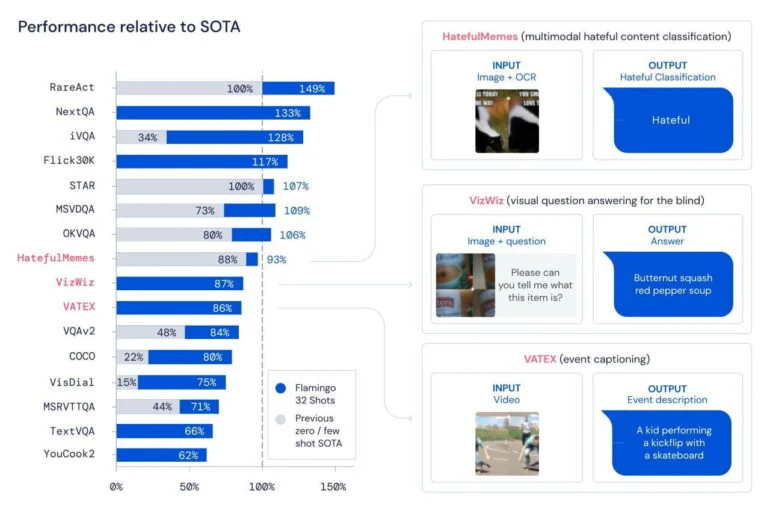
In 16 getesteten Bildverständnis-Benchmarks schlägt Flamingo andere Few-Shot-Ansätze. In diesen Tests muss Flamingo etwa Hatespeech auf Memes erkennen, Objekte identifizieren und beschreiben oder Ereignisse in einem Video benennen.

Mit nur 32 Beispielen und ohne Anpassung der Gewichte in den Modellen übertrifft Flamingo zudem in sieben Aufgaben die derzeit besten Methoden, die mit tausenden annotierten Beispielen feinjustiert wurden.
Flamingo kann außerdem mehr oder weniger sinnvolle Gespräche führen und dabei Informationen aus Bildern und Text verarbeiten. Im Dialog mit einem Menschen kann sich das Modell so auf Nachfrage, die auf einen möglichen Fehler hinweist, etwa eigenständig korrigieren.
Video: Deepmind
Die Ergebnisse repräsentieren laut den Forschenden einen wichtigen Schritt auf dem Weg zu einem allgemeinen visuellen Verständnis Künstlicher Intelligenz. Wie weit dieser Weg auch noch sein wird - die Verknüpfung großer KI-Modelle für multimodale Aufgaben wird dabei wohl eine tragende Rolle spielen.





